Руководство администратора#
Отказоустойчивая версия#
Для повышения высокой доступности и минимизации времени простоя системы разверните отказоустойчивую Акуру (HA).
Отказоустойчивая Акура обеспечивает высокий уровень доступности приложений и сервисов, что особенно актуально для критически важных систем. Использование нескольких узлов устраняет точки отказа и гарантирует непрерывную работу системы даже в случае аппаратных или программных сбоев. Связность между узлами предотвращает потерю данных при сбоях и позволяет оперативно восстановить состояние системы. Балансировка нагрузки эффективно распределяет трафик между узлами, исключая перегрузки, что обеспечивает стабильную производительность даже при пиковых нагрузках. Устранение неполадок в работе узлов выполняется без необходимости остановки системы, что делает такие решения надежной основой для бизнес-процессов.
Отказоустойчивые системы являются важным элементом инфраструктуры, который поддерживает стабильную работу бизнеса и минимизирует риски, связанные с отказами.
Для разворачивания отказоустойчивой версии достаточно
- трех виртуальных машин, работающих на базе Ubuntu 24.04,
- одной виртуальной машины для балансировщика нагрузки.
При необходимости увеличивайте количество узлов, адаптируя систему под потребности вашей организации.
Предварительная подготовка. Развертывание виртуальной машины#
Чтобы успешно развернуть отказоустойчивый кластер Акуры, разверните виртуальную машину
с помощью Python 3.11. Мы рекомендуем использовать Ubuntu 24.04, однако, если вы используете
более поздние версии, дополнительно установите pyenv для настройки Python 3.11.
Подробная инструкция находится здесь.
Этапы развертывания#
Шаг 1. Подготовьте группу безопасности#
Перед развертыванием ознакомьтесь со следующими правилами входящего трафика:
| Тип вещания | Протокол IP | Диапазон портов | Префикс удаленного IP | Удаленная группа безопасности | Описание |
|---|---|---|---|---|---|
| IPv4 | TCP | 1 - 65535 | - | acura_ha | Обратите внимание, что для созданной нами группы безопасности все порты TCP будут открыты. Это необходимо для связи Kubernetes между узлами (например, для кластеров etcd или MariaDB). |
| IPv4 | TCP | 22 (SSH) | <IP*>/32 | - | Разрешить порт TCP/22 с моего публичного IP для протоколов SSH и Ansible. |
| IPv4 | TCP | 80 (HTTP) | - | - | Порт пользовательского интерфейса Акуры перенаправляет пользователя на порт HTTPS. |
| IPv4 | TCP | 443 (HTTPS) | 0.0.0.0/0 | - | Порт пользовательского интерфейса Акуры |
| IPv4 | TCP | 4443 | 0.0.0.0/0 | - | Порт для начальных настроек |
| IPv4 | TCP | 6443 | 0.0.0.0/0 | - | Порт для доступа к службе API Kubernetes |
| IPv4 | UDP | 12201 | 0.0.0.0/0 | - | Порт для записи логов: используется агентами и модулями для отправки логов в стек ELK. |
IP* - IP-адрес для доступа к Акуре
Note
Развернутая виртуальная машина должна иметь доступ к порту 22 всех трех виртуальных машин и балансировщика нагрузки. В группе безопасности разрешен только один публичный IP для порта 22. Убедитесь, что ваша развернутая виртуальная машина использует этот публичный IP, или добавьте другое правило в группу безопасности.
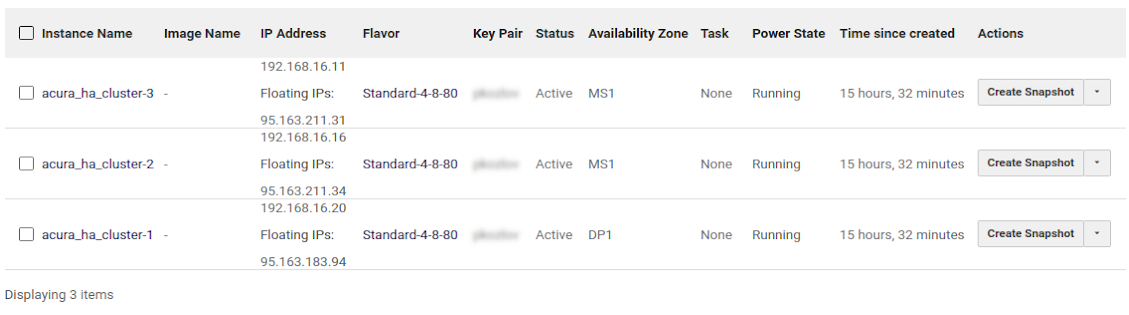
Шаг 2. Создайте три виртуальные машины#
Создайте три экземпляра Ubuntu 24.04 с томами по 200 ГБ (рекомендуется использовать SSD-диски). Все 200 ГБ должны быть доступны как один раздел, без отдельных разделов для /home и т. д. Также рекомендуется выделить не менее 16 ГБ оперативной памяти и 8 виртуальных ЦП для каждого экземпляра.
Пример:
Проверьте правильность DNS-серверов на всех узлах (cat /etc/resolv.conf).
Они должны быть доступны с DHCP-сервера. Например, результат команды nslookup должен выглядеть следующим образом:
$ nslookup google.com
Server: 8.8.8.8
Address: 8.8.8.8#53
Non-authoritative answer:cd
Name: google.com
Address: 64.233.165.113
Name: google.com
...
Если DNS-серверы не работают, проверьте конфигурацию DNS подсети (например, используйте 8.8.8.8 в качестве DNS-сервера). Имена хостов не должны быть полными доменными именами (FQDN); они не должны содержать точек.
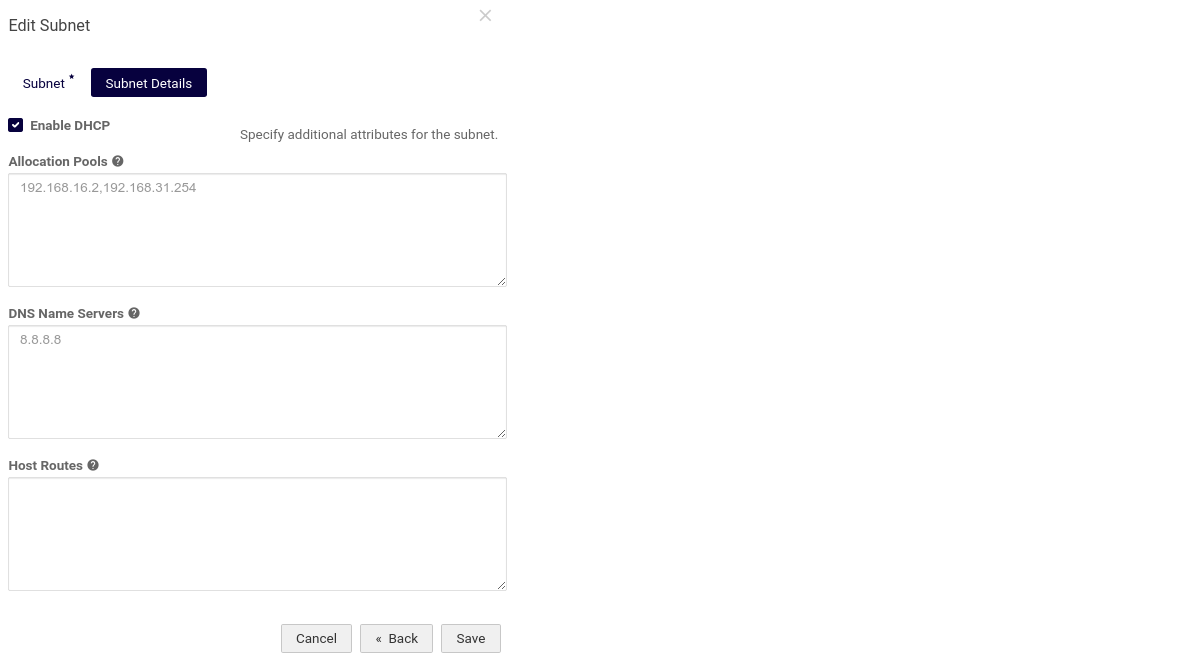
Шаг 3. Создайте балансировщик нагрузки#
Откройте следующие порты:
| Имя | Описание | Протокол | Порт |
|---|---|---|---|
| initconfig | Порт интерфейса начальной настройки | TCP | 4443 |
| http | Порт HTTP | TCP | 80 |
| k8s | Порт API сервисов Kubernetes | TCP | 6443 |
| https | Порт HTTPS для интерфейса Акуры | TCP | 443 |
Пример конфигурации облаке
Конфигурация NGINX
Не забудьте заменить X.X.X.X, Y.Y.Y.Y и Z.Z.Z.Z на IP-адреса ваших узлов. X.X.X.X - IP-адрес первого узла, Y.Y.Y.Y - второго и Z.Z.Z.Z - третьего.
$ cat /etc/nginx/nginx.conf
user www-data;
worker_processes auto;
worker_rlimit_nofile 70000;
pid /run/nginx.pid;
events {
worker_connections 70000;
# multi_accept on;
}
stream {
upstream stream_http {
least_conn;
server X.X.X.X:80;
server Y.Y.Y.Y:80;
server Z.Z.Z.Z:80;
}
upstream stream_https {
least_conn;
server X.X.X.X:443;
server Y.Y.Y.Y:443;
server Z.Z.Z.Z:443;
}
upstream stream_initial_config {
least_conn;
server X.X.X.X:4443;
server Y.Y.Y.Y:4443;
server Z.Z.Z.Z:4443;
}
upstream stream_kubernetes {
least_conn;
server X.X.X.X:6443;
server Y.Y.Y.Y:6443;
server Z.Z.Z.Z:6443;
}
upstream stream_elk {
least_conn;
server X.X.X.X:12201;
server Y.Y.Y.Y:12201;
server Z.Z.Z.Z:12201;
}
upstream stream_registry {
least_conn;
server X.X.X.X:15000;
server Y.Y.Y.Y:15000;
server Z.Z.Z.Z:15000;
}
server {
listen 80;
proxy_pass stream_http;
}
server {
listen 443;
proxy_pass stream_https;
proxy_buffer_size 10m;
}
server {
listen 4443;
proxy_pass stream_initial_config;
}
server {
listen 6443;
proxy_pass stream_kubernetes;
proxy_timeout 10s;
proxy_connect_timeout 10s;
}
server {
listen 12201 udp;
proxy_pass stream_elk;
proxy_timeout 30s;
proxy_connect_timeout 60s;
}
server {
listen 15000;
proxy_pass stream_registry;
}
}
Устранение неполадок
-
Если после изменения конфигурации у вас возникли проблемы с запуском или перезапуском NGINX, вы можете проверить правильность конфигурации с помощью команды:
nginx -t -
Если при запуске NGINX возникает ошибка, например, неизвестная директива «stream», добавьте следующую строку в начало конфигурации:
load_module /usr/lib/nginx/modules/ngx_stream_module.so;
Проверьте доступ по SSH из развернутой виртуальной машины к виртуальным машинам Акуры
Чтобы сэкономить время, проверьте доступ к порту 22 перед запуском любых установок. Это можно сделать с помощью простой команды Bash:
$ for i in X.X.X.X Y.Y.Y.Y Z.Z.Z.Z; do nc -vz -w 2 $i 22 ; done
Connection to X.X.X.X 22 port [tcp/ssh] succeeded!
Connection to Y.Y.Y.Y 22 port [tcp/ssh] succeeded!
Connection to Z.Z.Z.Z 22 port [tcp/ssh] succeeded!
X.X.X.X, Y.Y.Y.Y и Z.Z.Z.Z - целевые публичные IP-адреса. Если доступ невозможен, то вы увидите сообщения подобного рода:
$ for i in X.X.X.X Y.Y.Y.Y Z.Z.Z.Z; do nc -vz -w 2 $i 22 ; done
nc: connect to X.X.X.X port 22 (TCP) timed out: Operation now in progress
nc: connect to Y.Y.Y.Y port 22 (TCP) timed out: Operation now in progress
nc: connect to Z.Z.Z.Z port 22 (TCP) timed out: Operation now in progress
В этом случае, проверьте настройки группы безопасности.
Шаг 4. Подготовьте localhost#
1. Установите пакеты
sudo apt install python3-pip sshpass
pip3 install --upgrade pip==20.3.4
pip3 install "virtualenv<20.0"
2. Скачайте архив от Хайстекс по указанному URL адресу
3. Распакуйте архив “hystax-ha-archive.tar.gz”
tar xvzf hystax-ha-archive.tar.gz
4. Установите модули и пакеты, необходимые для работы
cd hystax_ha_archive
source venv.sh
pip install -r requirements.txt
В случае ошибки при установке, попробуйте следующую последовательность действий:
- установите пакет:
sudo apt install libffi-dev - повторите команду
pip install -r requirements.txt.
5. Создайте файл “ha_env_file” с описанием отказоустойчивой среды
<HOSTNAME1> ansible_ssh_host=<X.X.X.X>
<HOSTNAME2> ansible_ssh_host=<Y.Y.Y.Y>
<HOSTNAME3> ansible_ssh_host=<Z.Z.Z.Z>
Note
HOSTNAME1 — имя хоста первой машины Ubuntu, X.X.X.X — публичный IP-адрес первой машины Ubuntu и т. д.
Устранение неполадок
Если хосты Акуры используют разные SSH ключи (не ~/.ssh/id_rsa), для удобства добавьте их в файл ha_env_file:
ansible_ssh_private_key_file=<path_to_your_private_key>
Если вы используете защищенные паролем ключи SSH, добавьте их в SSH-агент:
1. Запустите в фоне SSH агента:
$ eval "$(ssh-agent -s)"
2. Добавьте закрытый ключ SSH к агенту:
$ ssh-add ~/.ssh/id_rsa"
Шаг 5. Установите мастера Kubernetes#
Разверните мастер Kubernetes HA
export ANSIBLE_HOST_KEY_CHECKING=False
ansible-playbook -e "ansible_ssh_user=<SSH_USER_NAME>" \
-e "lb_address=<LOAD_BALANCER_IP>" \
-e "ansible_python_interpreter=/usr/bin/python3" \
-e "logstash_host=127.0.0.1" \
-i ha_env_file ansible/k8s-master.yaml
Устранение неполадок
Если при введении команды требуется постоянный ввод пароля, используйте SSH ключи от
виртуальных машин, созданных на шаге 2.
Для этого добавьте приватные SSH ключи машин в файл ha_env_file, как описано на шаге 4
ansible_ssh_private_key_file=<path_to_your_private_key>
Это позволит избежать необходимости вводить пароль заново.
Если у пользователя нет прав root, добавьте к команде флаг -K, чтобы сразу при запуске сценария запрашивать пароль.
Шаг 6. Развертывание Акуры#
Воспользуйтесь следующей командой, чтобы развернуть кластер отказоустойчивой Акуры.
export ANSIBLE_HOST_KEY_CHECKING=False
ansible-playbook -e "ansible_ssh_user=<SSH USER NAME>" \
-e '{"overlay_list": ["overlay/ha.yaml", "overlay/golden-image.yml", "overlay/distr-dr.yaml", "overlay/startup_reconfigure.yaml"]}' \
-e "copy_patch=true" \
-e "copy_ca=true" \
-i ha_env_file ansible/ha-acura.yaml
Note
Данная команда разворачивает Акура для аварийного восстановления и резервного копирования. Если нужно развернуть решение для облачной миграции, замените название файла distr-dr.yaml на distr-migration.yaml.
После развертывания
1. Удостоверьтесь, что все поды Kubernetes запущены.
2. Настройте Акуру, для этого перейдите по адресу:
https://<LOAD-BALANCER-PUBLIC-IP>
Пример: https://89.208.86.10.
Практические инструкции#
Oбновить уже развернутую Акуру#
1. Выполните Шаг 4. Подготовьте localhost. После этого выполните команду, чтобы получить список существующих оверлеев, использованных при создании кластера:
kubectl exec -ti etcd-0 -- etcdctl get /overlay_list
При необходимости измените список оверлеев в etcd:
kubectl exec -ti etcd-0 -- etcdctl set /overlay_list ["old_overlay1","old_overlay2",<...>,"new_overlay"]
2. Выполните Шаг 6. Развертывание Акуры. При развертывании Акуры добавьте параметр
-e "update_cluster=true" в ansible-playbook. Например:
export ANSIBLE_HOST_KEY_CHECKING=False
ansible-playbook -e "ansible_ssh_user=<SSH_USER_NAME>" \
-e '{"overlay_list": ["overlay/ha.yaml", "overlay/golden-image.yml", "overlay/distr-dr.yaml", "overlay/startup_reconfigure.yaml", "overlay/big-heat-stack-timeout.yaml"]}' \
-e "copy_patch=true" \
-e "copy_ca=true" \
-e "update_cluster=true" \
-i ha_env_file ansible/ha-acura.yaml
Удалить неработающий узел из отказоустойчивой Акура#
1. Войдите на работающий узел.
2. Запустите команду, чтобы определить какой из узлов не работает:
kubectl get nodes
3. Выполните команду kubectl delete node <DEAD_NODE_NAME>, чтобы удалить неработающий узел из Kubernetes.
Вместо <DEAD_NODE_NAME> используйте имя узла с предыдущего шага.
4. Запустите команду, чтобы идентифицировать ID неработающего узла из etcd (первая колонка) Вместо <LIVE_NODE_NAME> используйте имя узла, с которого запускаете команду.
kubectl exec etcd-<LIVE_NODE_NAME> -n kube-system -- etcdctl --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key member list
5. Запустите команду, чтобы удалить нерабочий узел из кластера etcd. Вместо <LIVE_NODE_NAME> используйте имя узла, с которого запускаете команду. Вместо <DEAD_MEMBER_ID> используйте ID неработающего узла из etcd с предыдущего шага.
kubectl exec etcd-<LIVE_NODE_NAME> -n kube-system -- etcdctl --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key member remove <DEAD_MEMBER_ID>
Добавить новый узел#
1. Выполните действия из предыдущего раздела, для удаления неработающих узлов кластера.
2. Выполните шаги 2-3 из раздела по развертыванию новой виртуальной машины:
-
Настройте новую виртуальную машину с требуемыми параметрами.
-
Добавьте новую машину в конфигурацию балансировщика нагрузки.
3. Войдите на работающий узел и выполните следующие команды:
-
Создайте токен присоединения:
kubeadm token create --print-join-commandВ результате выполнения команда выведет
master_tokenиmaster_discovery_token. Скопируйте их в надежное место. -
Загрузите сертификаты:
sudo kubeadm init phase upload-certs --upload-certsВ результате выполнения команда выведет
master_cert_key. Скопируйте его в надежное место.
4. Действуйте согласно инструкции Шаг 4. Подготовьте localhost.
5. Используйте токены и ключ сертификата, сгенерированные ранее, для добавления нового узла в кластер:
source venv.sh
pip install -r requirements.txt
patch_url='<link-to-patch>'
ca_url='<link-to-ca-image>'
export ANSIBLE_HOST_KEY_CHECKING=False
ansible-playbook -e "ansible_ssh_user=<SSH_USER_NAME>" \
-e "ansible_python_interpreter=/usr/bin/python3" \
-e "lb_address=<LOAD_BALANCER_IP>" \
-e "logstash_host=127.0.0.1" \
-e "master_token=ae9wn..." \
-e "master_discovery_token=bf917..." \
-e "master_cert_key=4cc2c..." \
-e "copy_patch=true" \
-e "copy_ca=true" \
-i "<NEWLY_PROVISIONED_INSTANCE_IP>," \
ansible/k8s-add-node.yaml
Замечания
- Вместо
lb_addressукажите адрес балансировщика нагрузки. - Вместо
master_token,master_discovery_tokenиmaster_cert_keyукажите токены, которые вы получили ранее. Ознакомьтесь с примером, чтобы проверить формат. - После
-iустановите IP-адрес нового подготовленного экземпляра.
Резервное копирование внутренних баз данных Акуры#
Обзор#
Иногда машина, на которой развернута Акура, может выходить из строя. Чтобы не нарушать работу инфраструктуры, мы реализовали возможность создания резервных копий баз данных etcd, MariaDB и MongoDB, с возможностью их развертывания на резервной виртуальной машине.
Резервное копирование должно выполняться регулярно, для удобства процесс автоматизирован с помощью cronjob. Он разделён на два этапа: создание резервных копий и загрузка архива во внешнее хранилище.
Резервное копирование etcd и баз данных#
Параметры cronjob задаются через overlay. Например:
external_backup:
suspend: false
mountpoint: /acura/backup
schedule: "@daily"
keep: 5
name: &external_backup_name
startingDeadlineSeconds: 100
image:
repository: *external_backup_name
tag: local
- mountpoint – путь к локальному хранилищу резервных копий на машине Акуры
- keep – максимальное количество резервных копий для хранения
- name – имя архива для резервного копирования на внешнее хранилище
Резервное копирование сохраняет все ключи etcd в файл acura_etcd-<timestamp>.dump. Также выполняются shell-скрипты для экспорта MariaDB в acura_db_<timestamp>.sql.gz и коллекции events из MongoDB в acura_mongo_<timestamp>.json.gz. Хранятся только последние n файлов (см. параметр keep).
Все три файла по умолчанию архивируются в архив acura_etcd-<timestamp>.tar.gz.
Резервное копирование на внешнее хранилище#
Резервное копирование на внешнее хранилище копирует локально сохранённые резервные копии баз данных Акуры на удалённую виртуальную машину.
Параметры этой процедуры настраиваются в etcd. Если они не указаны, считается, что резервные копии хранятся только локально. Пример:
external_backup:
type: object-storage
key: username
secret: password
url: http://172.22.5.88:9000
bucket: some-bucket
region: some-region (optional)
backup_path: some/path/folder (optional)
- type – ожидаемые значения:
object-storageилиlocal - url – URL объекта хранилища
- bucket – имя бакета для хранения резервных копий
- region – регион хранилища (необязательный параметр)
- backup_path – путь для хранения архива резервного копирования (необязательный параметр)
Если какой-либо параметр отсутствует (кроме region и backup_path), процесс резервного копирования на внешнее хранилище не будет выполнен. Однако важно отметить, что в случае ошибки локальные резервные копии останутся на машине.
При запуске процедуры резервного копирования последние версии резервных копий etcd и баз данных архивируются в файл с именем acura_backup_<timestamp>.tar.gz. Если заданы соответствующие параметры, архив загружается в объектное хранилище (см. параметр backup_path). Если параметры хранилища не указаны, резервные копии остаются локальными.
Процесс восстановления#
После того как локальные резервные копии баз данных Акуры загружены на удалённую виртуальную машину, восстановите их, используя: hx_restore_from_backup.
Безопасность портов и управление функциями#
Сетевые порты и сервисы#
Контроллеры Акуры усилены с точки зрения безопасности, чтобы минимизировать поверхность атаки и упростить управление доступом.
Сервисы работают на следующих портах:
-
SSH —
tcp/22 -
HTTP (перенаправляется на 443, если включено) —
tcp/80 -
HTTPS —
tcp/443 -
Первоначальная конфигурация (автоматически закрывается после завершения настройки) —
tcp/4443 -
GELF logging —
tcp+udp/12201 -
Внутренний Docker-реестр (автообновление агентов, внешний агент репликации для oVirt/OpenStack в режиме docker-compose) —
tcp/15000
Доступ к веб-инструментам#
phpMyAdmin, панель метрик и журналы доступны по следующим адресам:
-
phpMyAdmin (по умолчанию отключён) →
https://<IP_ADDRESS_АКУРА>/tools/db -
Панель метрик (Grafana) →
https://<IP_ADDRESS_АКУРА>/tools/metrics
(уточните логин и пароль пользователя для доступа у нашей команды поддержки) -
Журналы →
https://<IP_ADDRESS_АКУРА>/tools/logs
(уточните логин и пароль пользователя для доступа у нашей команды поддержки)
Управление функциями через скрипты#
Для баланса между безопасностью и удобством предусмотрены удобные алиасы (hx_* скрипты) для включения или отключения функций, таких как phpMyAdmin, SSL и других.
Эти скрипты применяют изменения мгновенно — без необходимости перезапуска подов.
Чтобы воспользоваться ими:
-
Подключитесь к машине Акуры, введя команду:
ssh user@<IP_ADDRESS_АКУРА>Замените
<IP_ADDRESS_АКУРА>на реальный IP-адрес или имя хоста устройства.
Уточните пароль доступа у нашей команды поддержки. -
Выполните нужный скрипт
hx_*:-
Посмотреть версию Акуры:
hx_cluster_info -
Включить пользователя engineer (для некоторых систем, где он отключён по умолчанию, например AWS):
hx_enable_engineer -
Восстановить базы данных Акуры из файла резервной копии (см. Резервное копирование внутренних БД Acura):
hx_restore_from_backup -
Включить или отключить доступ к phpMyAdmin:
- включить на 12 часов:
hx_enable_phpmyadmin - отключить:
hx_disable_phpmyadmin
- включить на 12 часов:
-
Включить или отключить перенаправление SSL (HTTP → HTTPS):
- включить:
hx_enable_ssl_redirect - отключить:
hx_disable_ssl_redirect
- включить:
-
Панель метрик - Grafana#
Grafana — это мощный инструмент визуализации и мониторинга, который помогает быстро понять состояние системы.
В среде Акуры Grafana предоставляет готовые панели мониторинга с метриками в реальном времени: репликация, использование сети и узкие места в ресурсах.
Используя эти панели, администраторы могут быстро выявлять проблемы, оптимизировать производительность системы и отслеживать состояние процессов репликации.
Как интерпретировать данные#
Чтобы получить доступ к панелям Grafana, войдите по адресу:
https://<IP_ADDRESS_АКУРА>/tools/metrics
Уточните логин и пароль пользователя для доступа у нашей команды поддержки.
На главной панели (Home Dashboard) вы найдёте:
- список доступных полезных дашбордов;
- глобальную скорость репликации и использование сети.
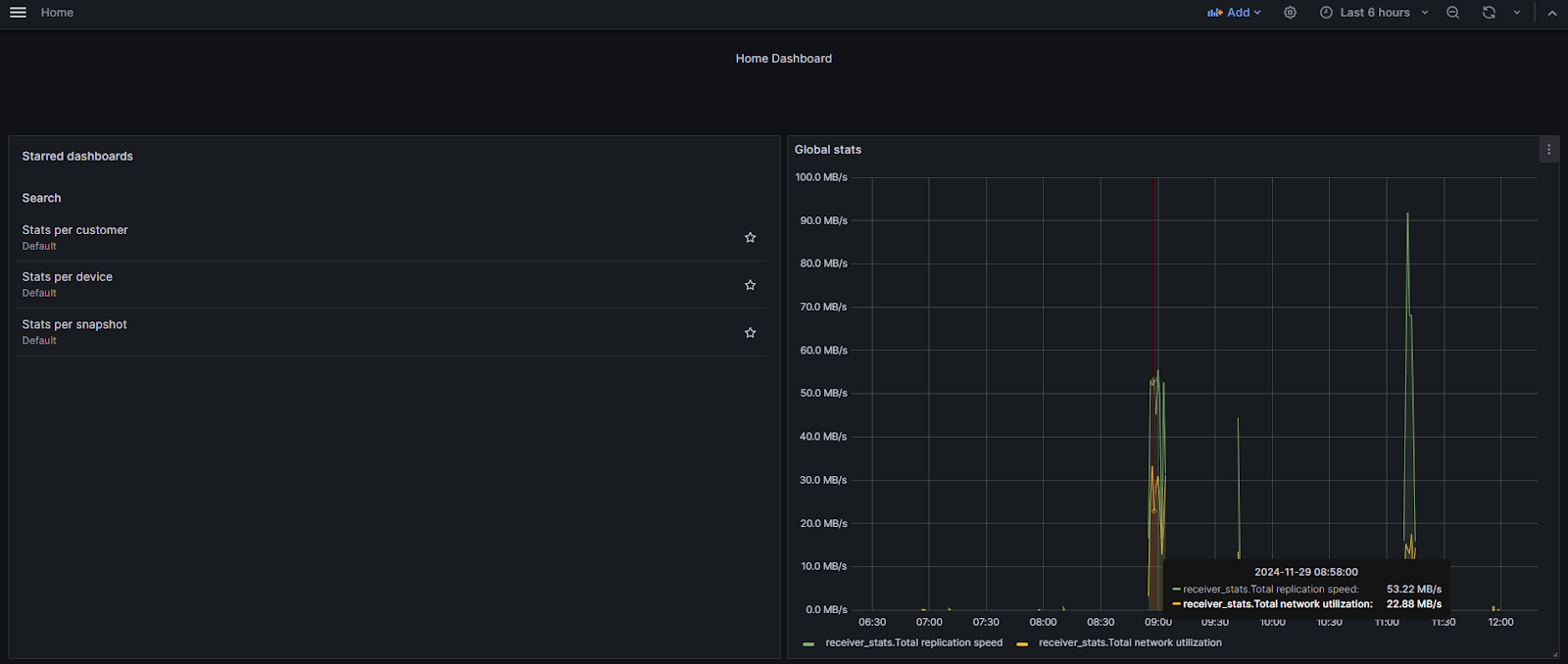
Для удобства три панели отмечены звёздочкой.
Найдите их в левой панели домашнего дашборда — это статистика по клиентам, устройствам и снимкам.
Каждая включает набор панелей:
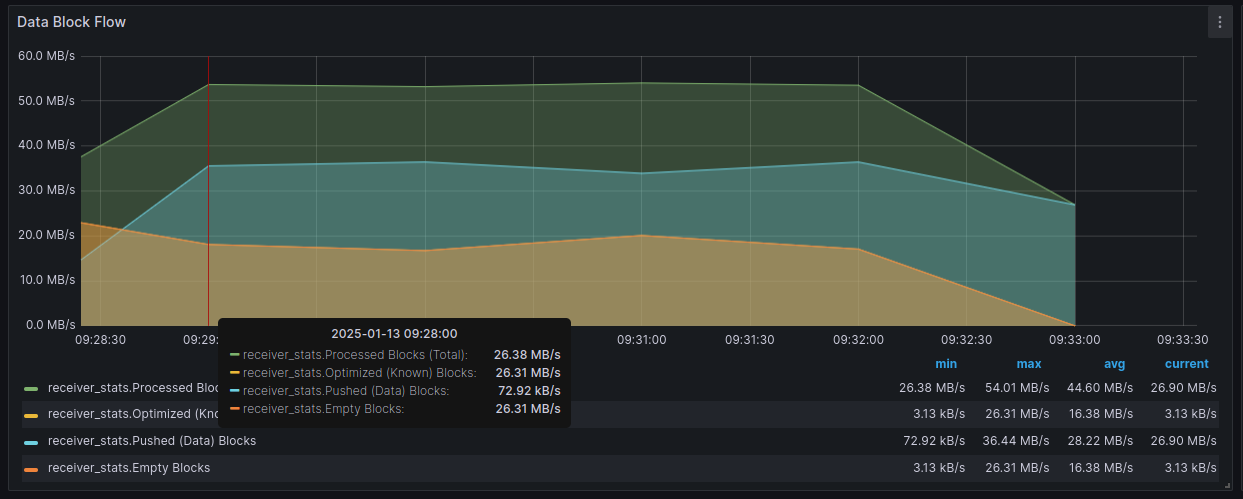
- Data Block Flow — измеряет скорость репликации с разбивкой по типам блоков.
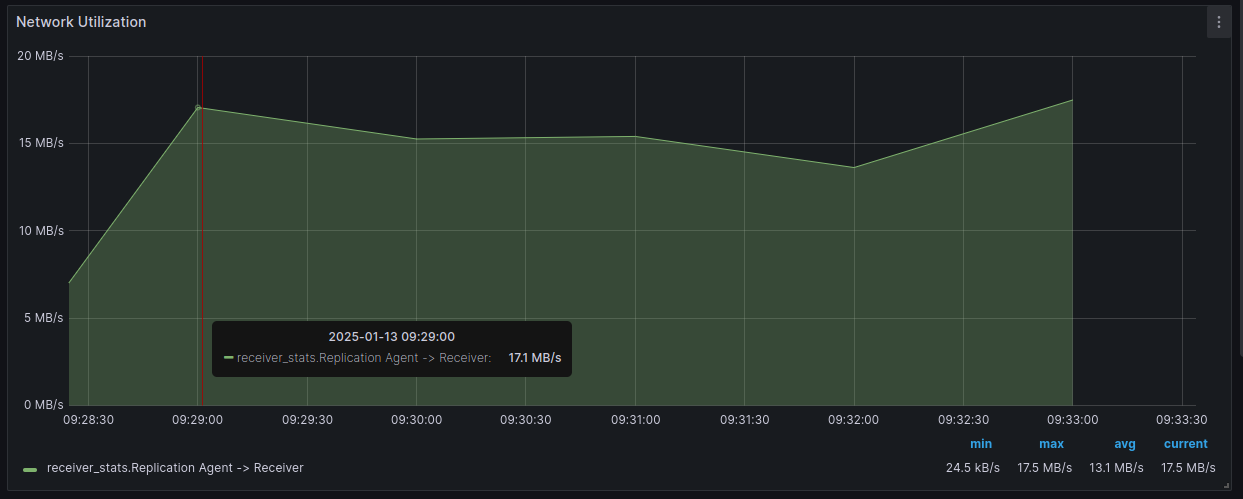
- Network Utilization — показывает фактический сетевой трафик (на данный момент только между репликационным агентом и Акуры, без трафика облачного агента).
-
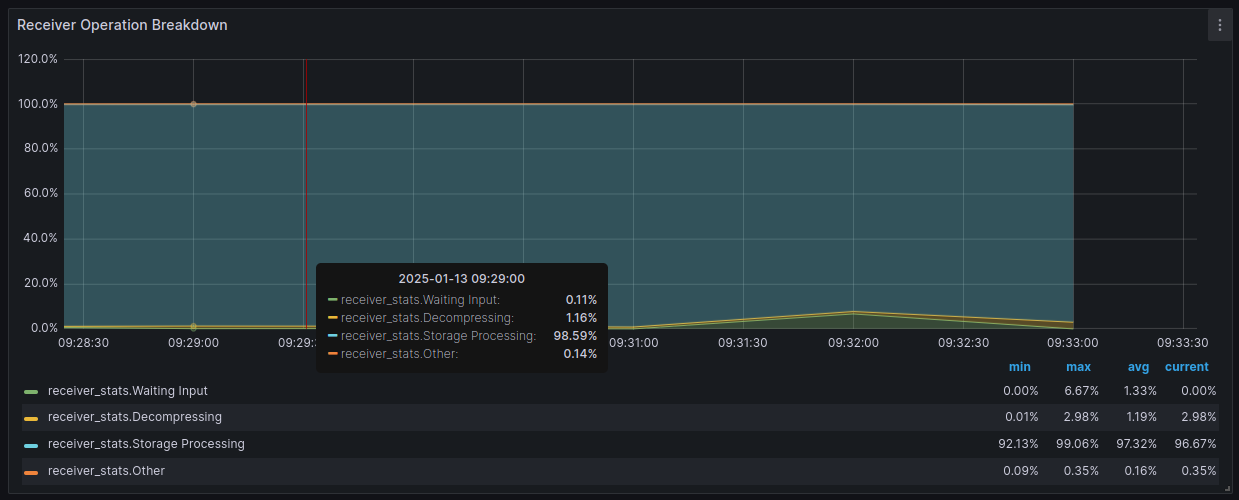
Receiver Operation Breakdown — отображает процент времени, который получатель тратит на выполнение различных операций.
Это помогает выявить узкие места: -
Если получатель большую часть времени ждёт входных данных — репликацонный агент не успевает читать или отправлять данные.
- Если получатель тратит больше времени на обработку хранения — облачный агент не справляется с приёмом или записью данных.
- Replication agent → Receiver Bandwidth optimization — показывает, сколько сетевого трафика удалось сэкономить за счёт сжатия и оптимизации WAN.
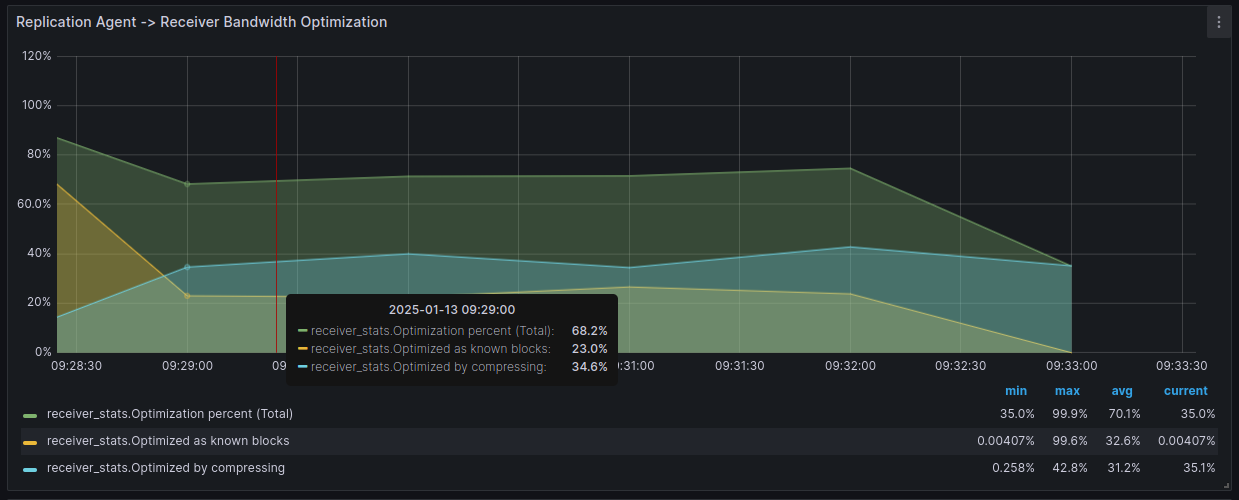
- Processing speed — измеряет скорость выполнения отдельных операций получатель и репликационный агент.
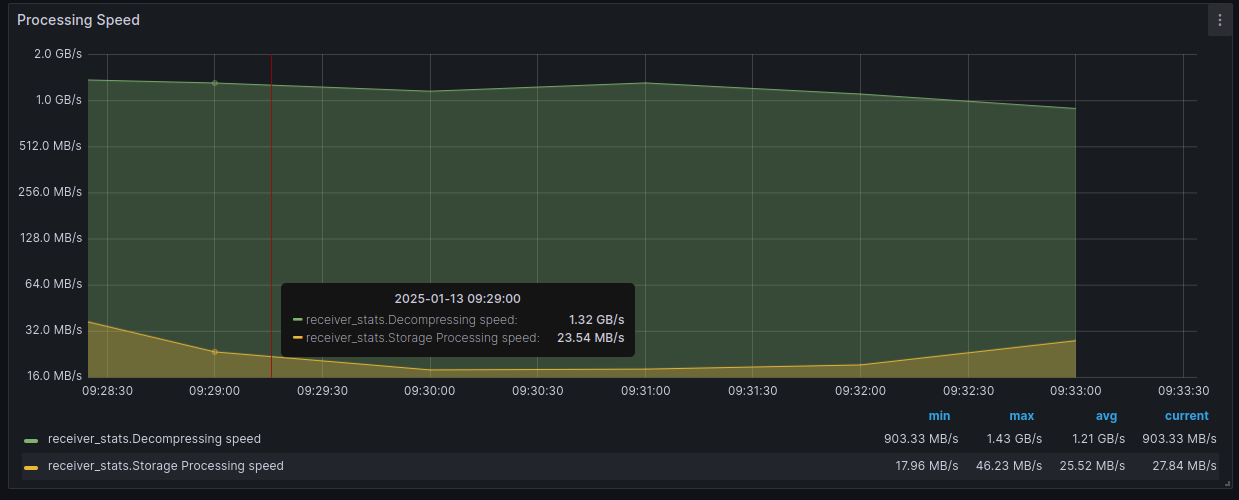
- Receiver threads — отображает количество активных потоков получателя.
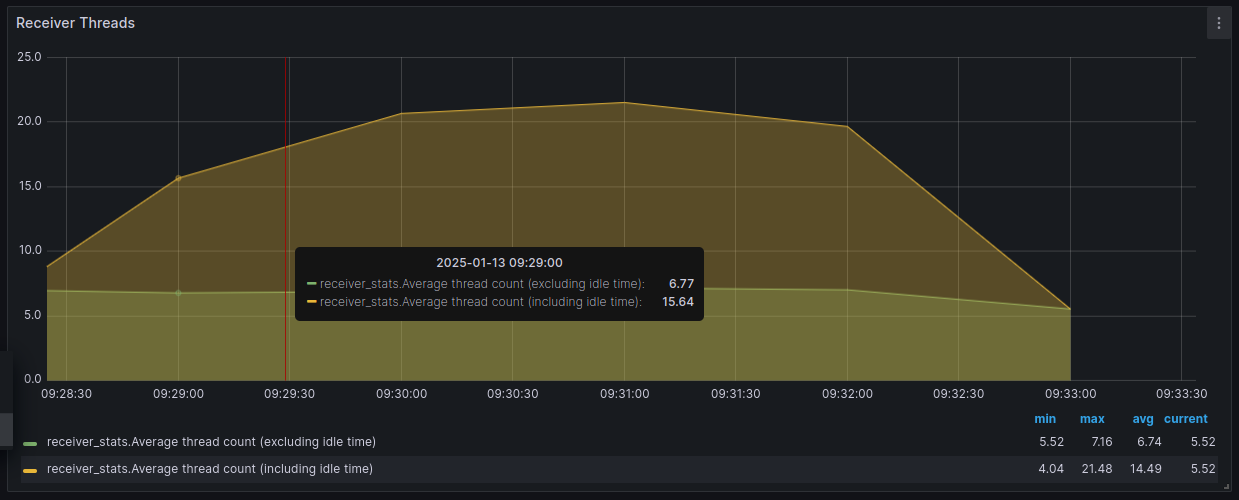
Чтобы увидеть подсказку, наведите курсор на нужный график.
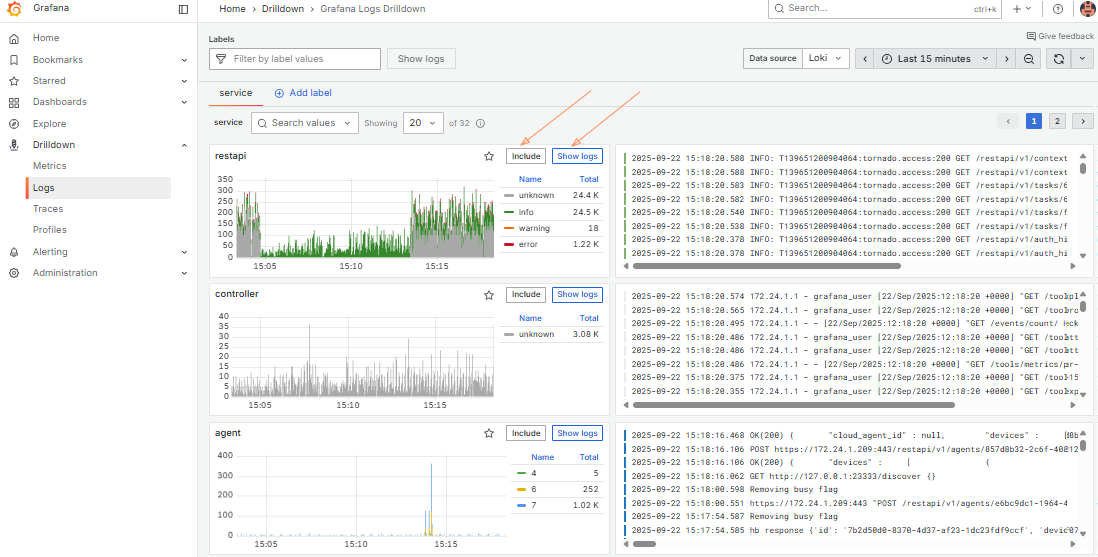
Как просматривать логи#
Существует два способа получить доступ к логам. Предварительно уточните логин и пароль пользователя для доступа у команды нашей технической поддержки.
1. Перейдите по адресу https://<IP_ADDRESS_АКУРА>/tools/logs.
2. Или откройте https://<IP_ADDRESS_АКУРА>/tools/metrics и перейдите в Drilldown → Logs.
На вкладке service главной страницы отображаются логи, сгруппированные по service_name.
Используйте этот вид, чтобы оценить общую ситуацию в кластере Акуры.
Для получения детальной информации по конкретному сервису используйте поле Labels для настройки фильтров под ваши нужды.
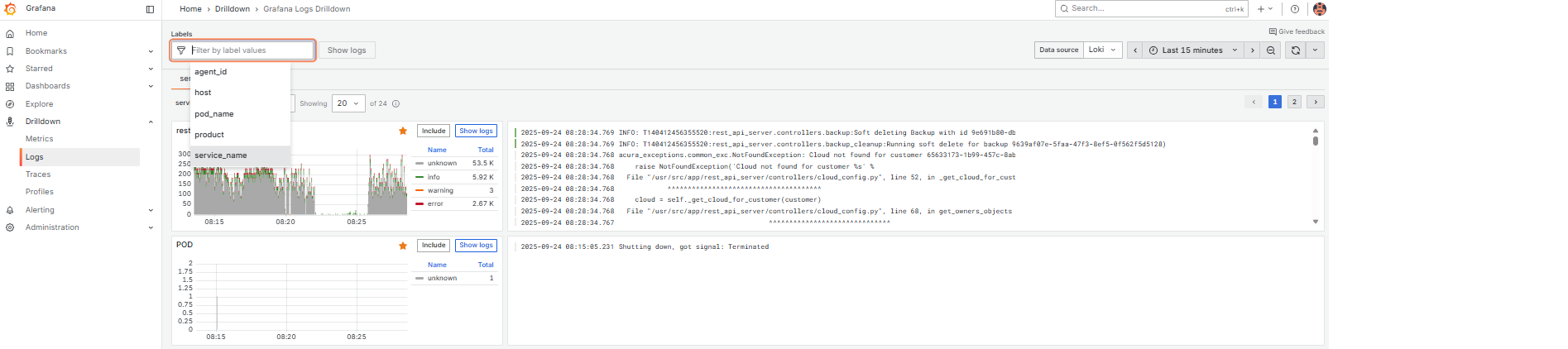
Используйте Log levels и Fields, чтобы точнее отфильтровать данные.
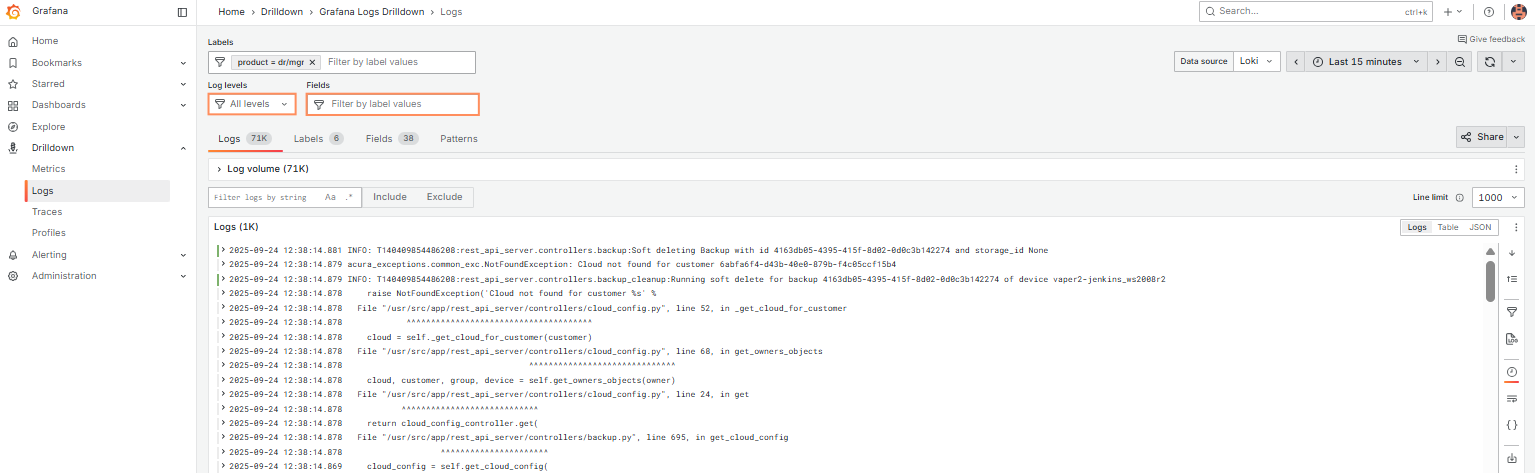
Разверните любую строку лога, чтобы увидеть все доступные метаданные и использовать быстрые элементы фильтрации.
Переключайтесь между вкладками, чтобы получить полную информацию.
Советы:
1. Используйте элементы управления временем и автообновлением в правом верхнем углу, чтобы задать интервал логов и частоту обновления.
2. Поле “Labels” позволяет фильтровать по меткам (service_name, agent_id и т. д.).
Удалите все метки, чтобы вернуться к общему обзору логов.
3. Поле “Fields” используется для фильтрации по структурированным метаданным (все поля, не являющиеся метками: customer_id, image_name и т. д.).
4. Воспользуйтесь “Search in log lines” для поиска по строкам логов.
Пробелы и спецсимволы разрешены — в отличие от Kibana, Grafana выполняет простой поиск подстрок, аналогичный grep.
- Чтобы выполнить поиск с условием AND (apple AND banana), введите
apple, нажмите Enter, затем введитеbananaи снова нажмите Enter — добавятся два фильтра. - Чтобы выполнить поиск с условием OR (apple OR banana), нажмите кнопку
.*, чтобы включить поиск по регулярным выражениям, и введите выражениеapple|banana.
5. Правая панель возле логов полезна: можно скрывать/показывать временные метки, автоматически разворачивать многострочные записи и скачивать отображённые логи.
6. Чтобы увидеть все логи Акуры в одном месте, используйте общую метку product, которая всегда равна dr или mgr.
7. Чтобы сгруппировать по нужным меткам, нажмите “Add label” (справа на вкладке service).
8. Для добавления фильтра:
- Нажмите Include, чтобы добавить несколько значений метки.
- Нажмите Show logs, чтобы отобразить логи для выбранных меток.