Процесс восстановления#
Процесс восстановления состоит из предварительного этапа, который представляет собой подготовку плана аварийного восстановления, и регулярного тестирования стратегии аварийного восстановления и действий в случае сбоя. "Действия в случае сбоя" означают настройку и запуск cloud site, изменение настроек запущенного cloud site, failback в продуктив и, наконец, удаление cloud site.
Доступные сценарии восстановления#
-
Восстановление в виде виртуальной машины
Вариант использования: запуск виртуальной машины из определенной точки восстановления. Последовательность шагов:

-
Восстановление файлов и папок
Вариант использования: просмотр и загрузка файлов и папок из определенной точки восстановления. Подробная информация. Последовательность шагов:

-
Присоединение дисков
Варианты использования: восстановление файлов и папок с использованием уже существующей виртуальной машины, восстановление базы данных из журналов транзакций. Используйте вместе со сценарием "Восстановление в виде виртуальной машины" на уровне подключения дисков из дополнительной точки восстановления. Подробная информация. Последовательность шагов:

-
Загрузка образа из failover
Вариант использования: один из сценариев восстановления после сбоя — загрузка резервных дисков в виде образов RAW. Подробная информация. Последовательность шагов:

-
Failback
Вариант использования: автоматическое создание виртуальной машины на исходном сайте из виртуальной машины, восстановленной на целевой площадке, выполнение периодических инкрементных синхронизаций. Операция доступна для исходных облаков VMware, Flexible Engine и OpenStack, требуется загрузка и развертывание агента Failback. Подробная информация. Последовательность шагов:

-
Загрузка образа виртуальной машины
Вариант использования: восстановление виртуальной машины на исходном сайте из образов дисков точки восстановления. В целях безопасности/очистки загрузка образа имеет TTL. Подробная информация.
Планы аварийного восстановления#
Планы аварийного восстановления --- это сценарии процесса восстановления, предназначенные на случай сбоя. Они включают в себя описание машин (количество vCPU, ОЗУ, ранг и т.д.) и сетей.
Самого существования актуального плана аварийного восстановления достаточно для быстрого восстановления в случае сбоя.
Создание плана аварийного восстановления#
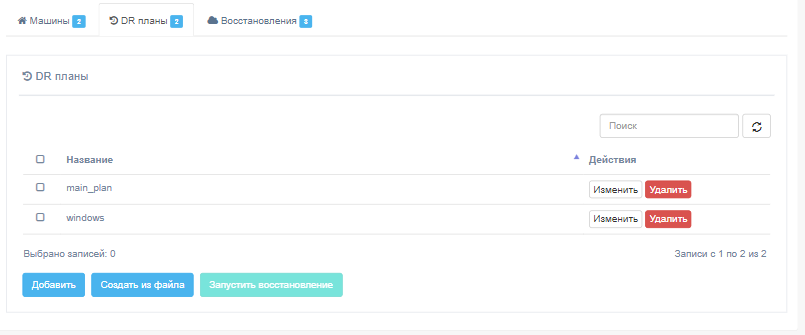
Чтобы создать план аварийного восстановления, просто нажмите кнопку Добавить на странице клиента.
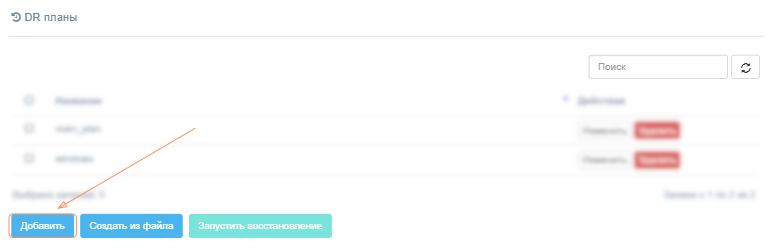
При добавлении нового плана укажите его название и содержимое плана. Название плана аварийного восстановления должно быть уникальным для клиента.
Существует два режима создания или редактирования плана: основной и расширенный. Чтобы переключаться между ними, выберите соответствующую вкладку на странице "Сгенерировать DR план".
В основном режиме пользователь может либо вставить/ввести сетевые спецификации для отказоустойчивой машины вручную, либо выбрать сети из списка, который Акура получает непосредственно из целевого облака. Список сетей может быть получен автоматически со следующих платформ - VMware, OpenStack, Flexible Engine, AWS, Azure.
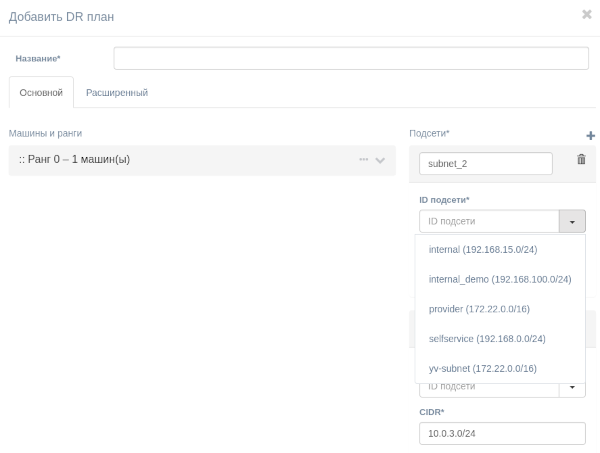
Расширенный режим позволяет указать более подробную конфигурацию в формате JSON.
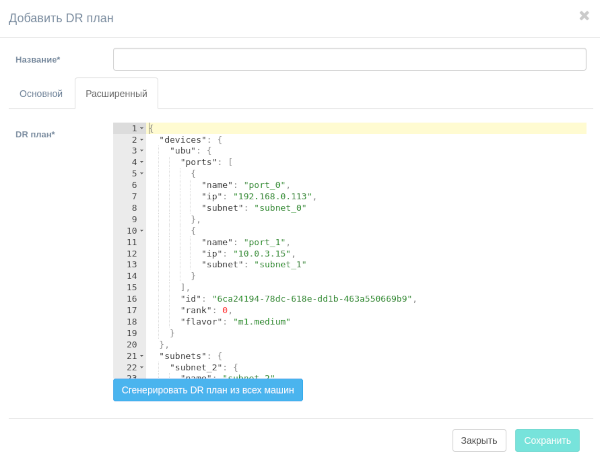
Основной частью плана аварийного восстановления является инструкция JSON для восстановления инфраструктуры и бизнес-приложения в DC.Чтобы сгенерировать план на основе всех клиентских машин, нажмите на Сгенерировать DR план из всех машин.
Создание плана аварийного восстановления для группы машин#
Можно создать план аварийного восстановления для отдельной машины, группы или на основе общих настроек. Чтобы создать план аварийного восстановления из группы машин для нескольких машин или групп, выберите нужные машины и нажмите кнопку Сгенерировать DR план в меню Групповые действия
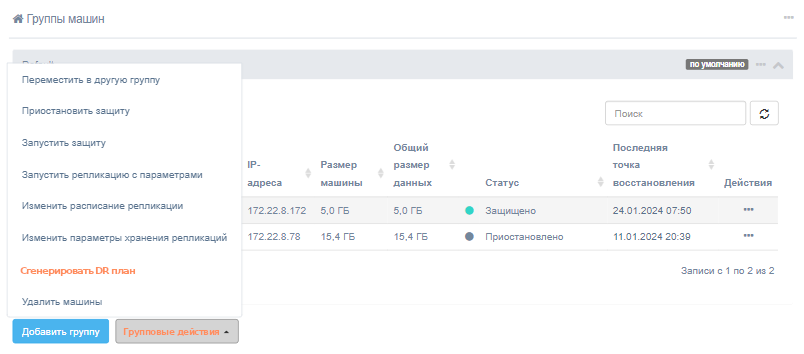
или в меню групп
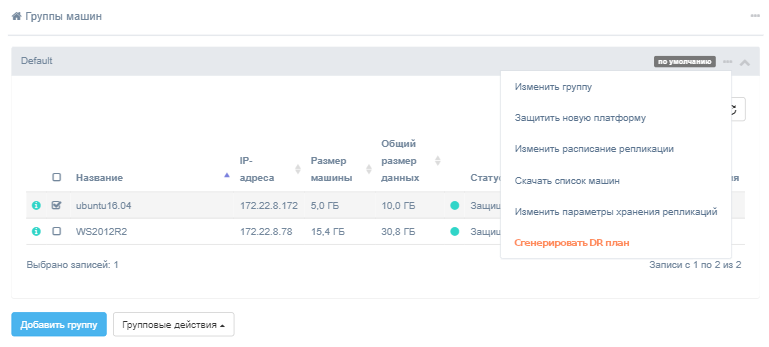
В результате появится диалоговое окно для создания и редактирования плана аварийного восстановления - дайте ему название. Название плана аварийного восстановления должно быть уникальным для клиента. Cодержимое плана будет сформировано на основании информации о выбранных машинах.
Создать план аварийного восстановления из файла#
Данный инструмент рекомендуется использовать для уже среплицированных машин. Особенно большую эффективеность он показал на большом количестве машин, т.к. значительно экономит время создания плана. Скачайте список машин. В загруженном файле machines_list.csv ряд полей будет заполнен на основании данных репликации. Обновите информацию в поле flavor, впишите cidr сети, в котором должна подняться машина, добавьте информацию о портах, в колонки, начинающиеся с ports.
При готовности загрузите файл. Для запуска создания плана аварийного восстановления нажмите Применить.
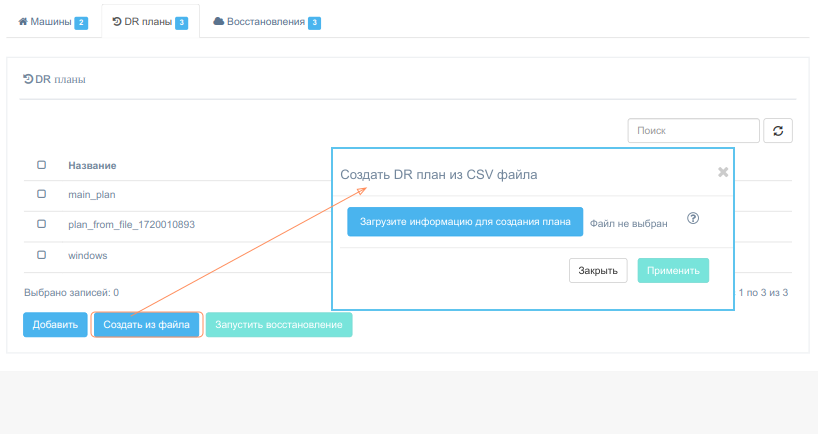
На создание плана аварийного восстановления потребуется некоторое время, после чего откроется окно. Отредактируйте название плана и другие поля, если нужно. Обратите особое внимание на предупреждающий текст оранжевого цвета в верхней части окна. Он показывает потенциально опасные места, из-за которых восстановление может отработать некорректно. Исправьте их на форме.
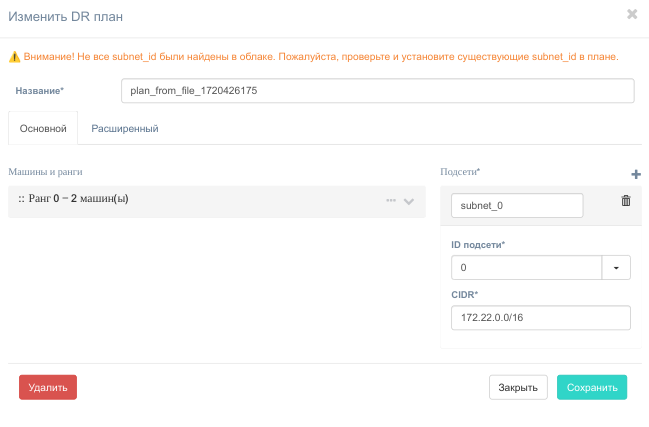
Сохраните план аварийного восстановления.
Синтаксис плана аварийного восстановления#
Основная часть плана аварийного восстановления представляет собой инструкцию JSON для восстановления инфраструктуры и бизнес-приложения в резервном DC.
Пример плана аварийного восстановления:
{
"devices": {
"IIS-Demo": {
"rank": 1,
"id": "52ce9361-b282-72b6-425a-f67347c5b79a",
"scheduler_hints": {
"group": "0c1b2901-7687-470e-a82c-6f69e92d5245"
},
"ports": [
{
"name": "port_0",
"ip": "192.168.15.112",
"subnet": "main_subnet"
},
{
"name": "port_1",
"subnet": "external"
}
]
},
"rhel7.2": {
"id": "522f3448-6a56-aa45-2131-207f7dda6664",
"ports": [
{
"name": "port_0",
"ip": "192.168.15.100",
"subnet": "main_subnet"
}
],
"rank": 0,
"boot_condition": {
"delay_seconds": 120,
"type": "wait"
}
}
},
"subnets": {
"main_subnet": {
"cidr": "192.168.15.0/24",
"subnet_id": "eda47a07-d1dd-4aca-ae8f-c652e997008e"
}
}
}
Базовые теги#
devices -- содержит описание каждой машины. Необходимо перечислить все машины, которые должны быть воссозданы в cloud site:
{
"devices": {
"rhel7.2": {
"id": "522f3448-6a56-aa45-2131-207f7dda6664",
"ports": {
"port_0": {
"ip": "192.168.15.100",
"subnet": "main_subnet"
},
"scheduler_hints": {
"group": "0c1b2901-7687-470e-a82c-6f69e92d5245"
}
},
"rank": 0,
"boot_condition": {
"delay_seconds": 120,
"type": "wait"
}
}
}
}
subnets -- содержит описание сетей, которые необходимо воссоздать в резервном DC:
{
"subnets": {
"main_subnet": {
"cidr": "192.168.15.0/24",
"subnet_id": "eda47a07-d1dd-4aca-ae8f-c652e997008e"
}
}
}
Синтаксис описания машины#
Описание машины состоит из ряда параметров, описывающих свойства машины, таких как название машины, сетевые настройки, ранг и условия загрузки машин для поддержания последовательности и согласованности процесса запуска cloud site.
{
"rhel7.2": {
"id": "522f3448-6a56-aa45-2131-207f7dda6664",
"custom_image_metadata": {
"hw_qemu_guest_agent": "no",
"os_require_quiesce": "no",
"my_os_type": "linux-custom",
"hw_disk_bus": "scsi",
"hw_scsi_model": "virtio-scsi",
"my_custom_image_tag": "linux"
},
"security_groups": [
"sg-1",
"sg-2"
],
"availability_zone": "zone-1",
"user_data": "#!/bin/bash\nrpm -e hlragent\nrm -rf /etc/hystax\n",
"ports": {
"port_0": {
"ip": "192.168.15.100",
"subnet": "main_subnet"
}
},
"rank": 0,
"scheduler_hints": {
"group": "0c1b2901-7687-470e-a82c-6f69e92d5245"
},
"boot_condition": {
"delay_seconds": 120,
"type": "wait"
}
}
}
Параметры описания машин:
| Параметр | Описание | Обязательность |
|---|---|---|
| machine_name | Базовый тег для описания машины. Имя будет использоваться для идентификации машины на cloud site. | Да |
| fix_dev_prefix | Введите префикс, если необходимо обновить названия дисков машины c ОС Linux во время P2V. Возможные значения: - ‘sd’ (для названий вида /dev/sda1), - ‘vd’ (для названий вида /dev/vda1), - ‘xvd’ (для названий вида /dev/xvda1). Названия дисков заменяются в рамках процесса P2V для Linux в следующих файлах (несуществующие файлы пропускаются): - /etc/fstab, - /boot/grub/grub.cfg (а также /grub/grub.cfg, если /boot – отдельный раздел), - /boot/grub2/grub.cfg (а также /grub2/grub.cfg, если boot – отдельный раздел). Например: { "devices": { "ds-debian10-sda": { "fix_dev_prefix": "vd", ... } } } |
Нет |
| id | Внутренний идентификатор машины (можно найти, наведя курсор мыши на название машины в списке машин на странице клиента). | Да |
| ports | Список конфигураций сетевых интерфейсов машины (может быть несколько). Интерфейсы будут добавлены в том же порядке, в котором они описаны. Описание параметров интерфейса и примера их использования приведено ниже. | Да |
| scheduler_hints | Дополнительные параметры планировщика при настройке отказоустойчивости. Параметр group позволяет указать группу серверов, в которой будут размещаться инстансы для отказоустойчивого запуска в OpenStack.Пример: "scheduler_hints": { "group": "0c1b2901-7687-470e-a82c-6f69e92d5245" } |
Нет |
| rank | Порядок, в котором будет запущена группа машин. Например, машины с рангом 2 будут запущены только после запуска всех машин с рангом 1, а те, в свою очередь, только после запуска всех машин с рангом 0. | Да |
| boot_condition | Состояние, в котором машина считается работающей. Поддерживается задержка во времени; по её истечении машина считается запущенной. Условие распространяется на весь ранг. Если есть несколько машин с задержкой по времени, ранг считается выполненным после ожидания в течение самого длительного времени. Синтаксис: "boot_condition": { "delay_seconds": number of seconds to wait, "type": "wait" } Пример: "boot_condition": { "delay_seconds": 120, "type": "wait" } |
Нет |
| flavor | Название или идентификатор существующей конфигурации в облаке. Для VMware значение указывается как vCPU-RAM, например 2-4, что означает 2 vCPU и 4 ГБ. Пример: “flavor”: “2-4” |
Да |
| config_drive | По умолчанию – false. Установите в true, если хотите использовать конфигурационный диск. Пример: "config_drive": "true" |
Нет |
| security_groups | Список групп безопасности, которые будут использоваться для машины. Это приведёт к перезаписи группы (групп) по умолчанию. | Нет |
| availability_zone | Название зоны доступности, используемой для машины. Это приведёт к перезаписи зоны доступности, указанной в настройках облака. | Нет |
| user_data | Сценарий, который будет выполнен на целевой машине. Чтобы использовать ключ “user_data”, на исходной машине должен быть установлен cloud_init, в противном случае он будет проигнорирован. | Нет |
| firmware | Параметр, который выбирает вариант загрузки для машины (Vmware, oVirt, GCP). Доступные значения - BIOS (по умолчанию) или EFI. Пример: “firmware”: “EFI” |
Нет |
| guest_id | Идентификатор гостевой операционной системы. Обратитесь к официальной документации VMware. Пример: “guest_id”: “ubuntu64Guest”. |
Нет |
| hardware_ver | Аппаратная версия виртуальной машины. Обратитесь к официальной документации VMware. Пример: “hardware_ver”: “vmx-11”. |
Нет |
| byol (только для AWS) | Если byol - false (или не установлен), то используется AWS ImportImage (AWS запускает собственную P2V). Если byol - true, то используется AWS RegisterImage, и запускается наш собственный P2V. Пример: "devices": { "sd_small_ubuntu": { "rank": 0, "byol": true, } } |
Нет |
| ntp_server (только для Windows) | Протокол, используемый Windows для синхронизации. Пример: "devices": { "im-WS2019-ntp": { "flavor": "m1.medium", "ports": [ { "name": "port_0", "subnet": "provider-subnet" } ], "id": "52eef058-012b-70dd-9271-28ee5f56d171", "rank": 0, "ntp_server": "ntp6.ntp-servers.net" }, "subnets":{ "provider-subnet": { "name": "provider-subnet", "subnet_id": "6129317f-4987-4bf3-bfd0-c0edc3bc4bba", "cidr": "172.24.1.0/24" } } } |
Нет |
| hostname (только для Windows машин в облаке OpenStack) | Новое имя хоста Windows машины. Значение поля может принимать значения: - true (по умолчанию) – использовать имя машины из плана в качестве имени хоста - false – не менять имя хоста - любая строка – установить имя хоста как указано в строке. Пример: "devices": { "ds2012test": { "id": "9f51d0de-b6cb-400e-b223-5e748cc39d01", "flavor": "m1.medium", "hostname": "my-super-long-custom-hostname", "rank": 0, "ports": [ { "name": "port_0", "subnet": "DS-internal-2" } ] } }, "subnets": { "DS-internal-2": { "name": "DS-internal-2", "subnet_id": "76377dae-4e35-4183-bafa-b06eef69249e", "cidr": "172.22.0.0/16" } } |
Нет |
| rclocal_script | Сценарий, который запустится при загрузке Linux. Пример: "rclocal_script": "#!/bin/bash\ndate > date.txt\n" |
Нет |
| copy_efi_bootloader | По умолчанию – false. Установите в true, если хотите использовать загрузчик по умолчанию. Пример: "copy_efi_bootloader": true |
Нет |
| key_name | Ключ-пара для устройства. Пример: "key_name": "yv-key" |
Нет |
| meta | Список мета-тегов машины. Для OpenStack, OpenNebula. Пример: "devices": { "rhel7.2": { ... "meta": { "Image Name": "Hystax_CATI_...", "Image ID": "f389c03b-...", "Image": "image", "Key Name": "username" } } |
Нет |
| custom_image_metadata | Задать пользовательские метаданные образа для среплицированных ВМ. Только OpenStack. Пример: "custom_image_metadata": { "hw_qemu_guest_agent": "no", "os_require_quiesce": "no", "my_os_type": "linux-custom", "hw_disk_bus": "scsi", "hw_scsi_model": "virtio-scsi", "my_custom_image_tag": "linux" }, Параметр можно задать как строку с объектом JSON: "custom_image_metadata": "hw_qemu_guest_agent=no,os_require_quiesce=no,my_os_type=linux-custom,hw_disk_bus=scsi,hw_scsi_model=virtio-scsi,yv_custom_image_tag=Linux". Также этот параметр можно задать как дополнительную опцию на этапе “Установки и начальной настройки решения” или при добавлении облака. Обратите внимание, что, если параметр задан и на этапе начальной конфигурации/добавления облака, и в DR плане, то к облаку будут применены настройки DR плана, т.к имеют приоритет выше, даже если значение представляет собой пустую строку. |
Нет |
Описание интерфейса ports имеет следующие параметры:
| Параметр | Описание | Обязательность |
|---|---|---|
| name | Название интерфейса | Да |
| ip | IP-адрес интерфейса. По умолчанию адаптеры Windows будут настроены как DHCP. Если вы хотите установить статические настройки, то используйте это поле совместно с mac. |
Нет |
| mac | MAC-адрес интерфейса. Игнорируется для облака AWS. | Нет |
| subnet | Название подсети интерфейса | Да |
| routing_allowed | Позволяет машине быть маршрутизатором (может быть “true” или “false” (по умолчанию)). Игнорируется для облака AWS. | Нет |
| floating_ip | добавляет floating_ip для порта (может быть “true” или “false” (по умолчанию)). Использование этого параметра со значением “true” ограничивает устройство наличием только одного порта. “floating_ip”: “ |
Нет |
| mtu (только для Windows) | Наибольший размер пакета, отправляемый по сети без фрагментации. Используйте этот параметр в паре с параметром mac. Пример: "devices": { "DS2012R2MULMBR": { "id": "9f51d0de-b6cb-400e-b223-5e748cc39d01", "flavor": "m1.medium", "rank": 0, "ports": [ { "name": "port_0", "ip": "172.22.8.249", "mac": "08:00:27:46:79:29", "gateway_ip": "172.22.1.2", "dns_nameservers": [ "172.22.1.2", "8.8.4.4" ], "mtu": 1511, "subnet": "DS-internal-2" } ] } }, "subnets": { "DS-internal-2": { "name": "DS-internal-2", "subnet_id": "76377dae-4e35-4183-bafa-b06eef69249e", "cidr": "172.22.0.0/16" } } |
Нет |
Примеры:
"ports": [
{
"name": "port_0",
"ip": "192.168.15.100",
"subnet": "main_subnet"
}
]
Порты, подсети, mac, ip, gateway и dns. Используйте mac, чтобы установить статический ip:
{
"devices": {
"sd_small_ubuntu": {
"rank": 0,
"ports": [
{
"name": "port_0",
"ip": "172.22.8.144",
"mac": "08:00:27:46:79:27",
"gateway_ip": "172.22.1.2",
"dns_nameservers": [
"172.22.1.2",
"172.22.1.3"
],
"subnet": "subnet_1"
}
],
"id": "5260881c-c921-f037-df78-6105f018a9c2",
"flavor": "m1.medium"
}
},
"subnets": {
"subnet_1": {
"name": "subnet_1",
"cidr": "172.22.0.0/16"
}
}
}
Пример для случая, если IP динамический:
{
"devices": {
"centos": {
"ports": [
{
"name": "port_0",
"floating_ip": true,
"subnet": "subnet_0"
}
]
<...>
}
}
}
Синтаксис описания сети#
Описание сети состоит из ряда параметров, таких как название сети, её CIDR и адреса DNS-серверов.
Пример:
{
"subnets": {
"main_subnet": {
"cidr": "192.168.15.0/24",
"subnet_id": "eda47a07-d1dd-4aca-ae8f-c652e997008e"
}
}
}
Параметры описания сети:
| Параметр | Описание | Обязательность |
|---|---|---|
| network name | Название сетевого идентификатора является базовым тегом для описания сети | Да |
| cidr | CIDR сети | Да |
| subnet_id | Существующий идентификатор подсети в целевом облаке | Да |
Warning
Указанный идентификатор подсети должен быть доступен для используемой зоны доступности.
Редактирование существующего плана аварийного восстановления#
Чтобы отредактировать существующий план аварийного восстановления, нажмите кнопку Изменить напротив этого плана на странице клиента.
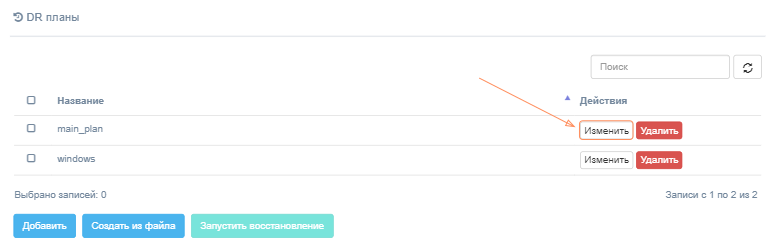
Появится диалоговое окно, в котором можно отредактировать план аварийного восстановления.
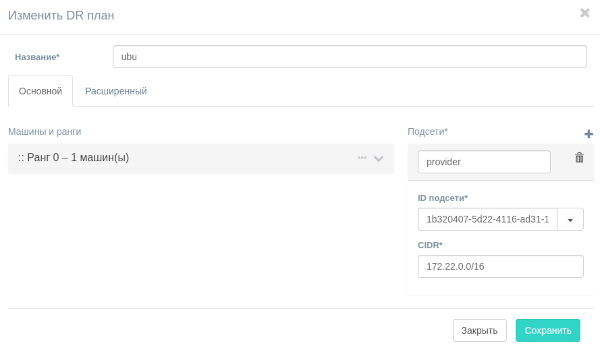
Тестирование планов аварийного восстановления#
Защита от сбоев не ограничивается единовременным созданием плана аварийного восстановления. Необходимо постоянно проверять его актуальность и проводить регулярное тестирование стратегии аварийного восстановления с рекомендуемой частотой один раз в 3-4 недели. Для выполнения этой проверки будет достаточно следующих шагов:
- создавайте cloud sites из плана аварийного восстановления с определённой регулярностью;
- проводите набор тестов (они должны быть подготовлены как часть стратегии аварийного восстановления и адаптированы к инфраструктуре заказчика; заказчик и поставщик услуг аварийного восстановления несут взаимную ответственность за их подготовку).
После получения результатов тестирования план аварийного восстановления соответствующим образом корректируется (путём добавления описаний новых машин, удаления устаревших) и выполняется последовательность устранения неполадок в процессе восстановления в случае проблем с бизнес-приложением клиента. Например, при запуске одной из машин может появиться синий экран (BSOD).
Этапы тестирования:
- Обновите план аварийного восстановления.
- Создайте cloud site из текущей точки восстановления.
- Запустите набор тестов на работающем cloud site.
- Обновляйте и корректируйте план аварийного восстановления, устраняйте неполадки.
Выполнение этих шагов позволяет заказчику заранее подготовиться к сбою и свести к минимуму связанные с этим проблемы.
Восстановление во время аварии#
В случае аварии запустите cloud site (failover), чтобы восстановить работоспособность бизнес-приложения на резервном сайте. Используйте ранее подготовленный план аварийного восстановления в качестве сценария восстановления.
Подробное описание конфигурации процесса восстановления можно найти в разделе ACP - Процесс восстановления.
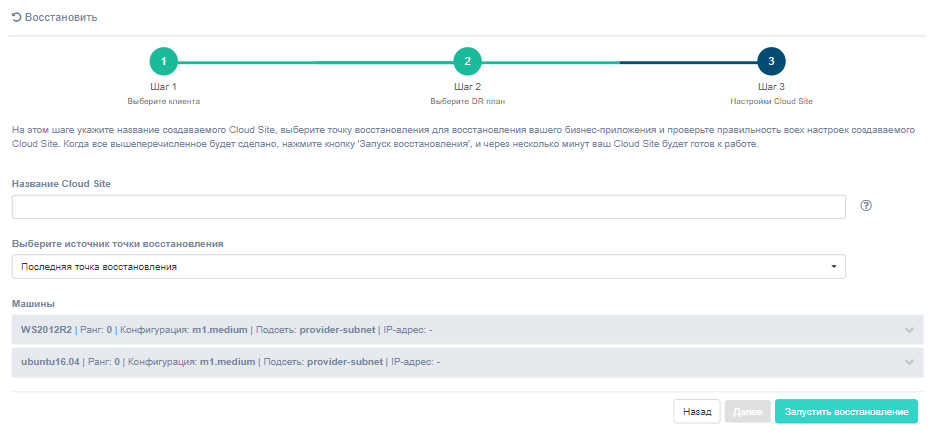
Процесс восстановления может потребовать некоторого времени: его продолжительность зависит от сложности структуры плана аварийного восстановления и уровней согласованности/зависимости между компонентами бизнес-приложения. Как только все компоненты получат статус Активен, бизнес-приложение готово к работе, и можно переходить к следующему этапу, который включает в себя перенос основного трафика на резервный сайт и настройку отдельных компонентов.
Warning
Перенаправление основного трафика на резервный сайт не является частью текущей функциональности решения и должно быть заранее согласовано с поставщиком услуг.
В целях экономии времени рекомендуется использовать упрощённый набор тестов, которые будут выполняться на cloud site, прежде чем переключать производственный трафик на новую цель.
Настройки Cloud Site#
После создания cloud site можно выполнить ряд дополнительных действий для настройки среды выполнения бизнес-приложения, таких как добавление машин на cloud site, остановка/запуск машин. Описание cloud sites и соответствующих настроек.
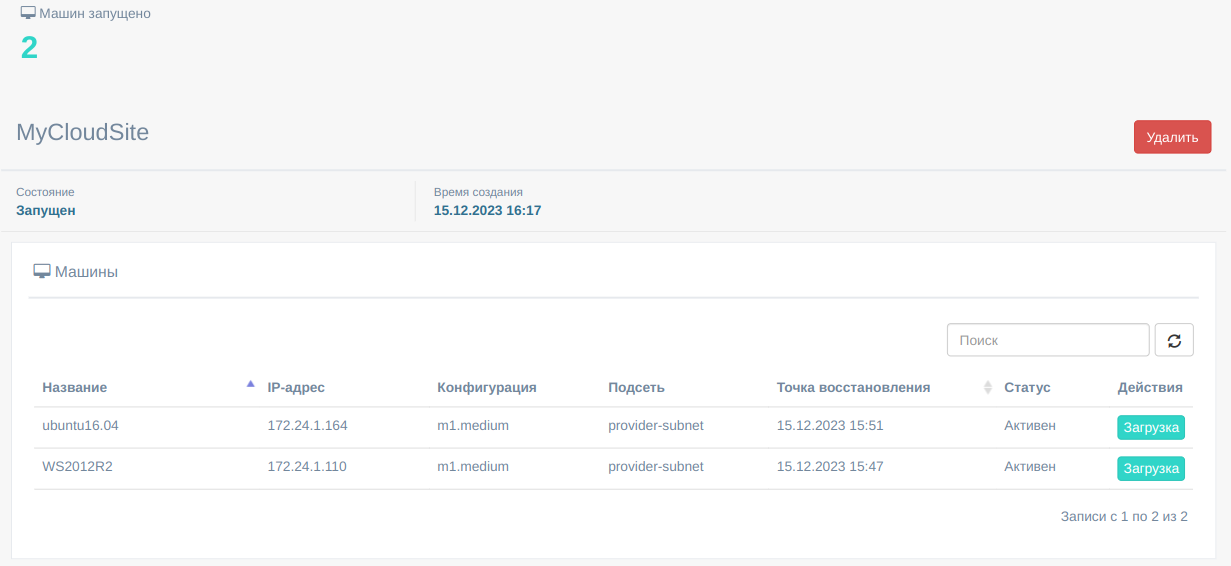
Во время тестирования стратегии аварийного восстановления или после восстановления основного сайта и согласования накопленных изменений рекомендуется удалить избыточные cloud sites, чтобы освободить затраченные на них ресурсы.
Failback в продуктив#
После восстановления основного сайта после аварии обычно требуется выполнить failback бизнес-приложения в исходное состояние со всеми изменениями, накопленными на платформе резервного копирования с момента запуска cloud site, и соответствующим образом перенаправить пользовательский трафик.
Процесс состоит из:
- Загрузки агента с подготовленным планом аварийного восстановления, запуск его в рабочей среде для загрузки изменений с последней точки восстановления.
- Тестирования бизнес-приложения в производственной среде.
- Остановки машин на cloud site для завершения изменений.
- Загрузки изменений с запущенного cloud site в новую рабочую среду.
- Запуска машин в продуктив и перенаправление трафика соответствующим образом.
- Защиты нового продуктива.
Как только эти шаги будут выполнены, бизнес-приложение вернётся к работе со всеми изменениями, накопленными с момента перенаправления трафика на резервный сайт.
Чтобы запустить failback, нажмите на пункт меню Failback на левой боковой панели.
Failback включает в себя пять (для партнёра) или четыре (для клиента) шага.
Для партнёра первым шагом является выбор клиента, которому требуется failback.
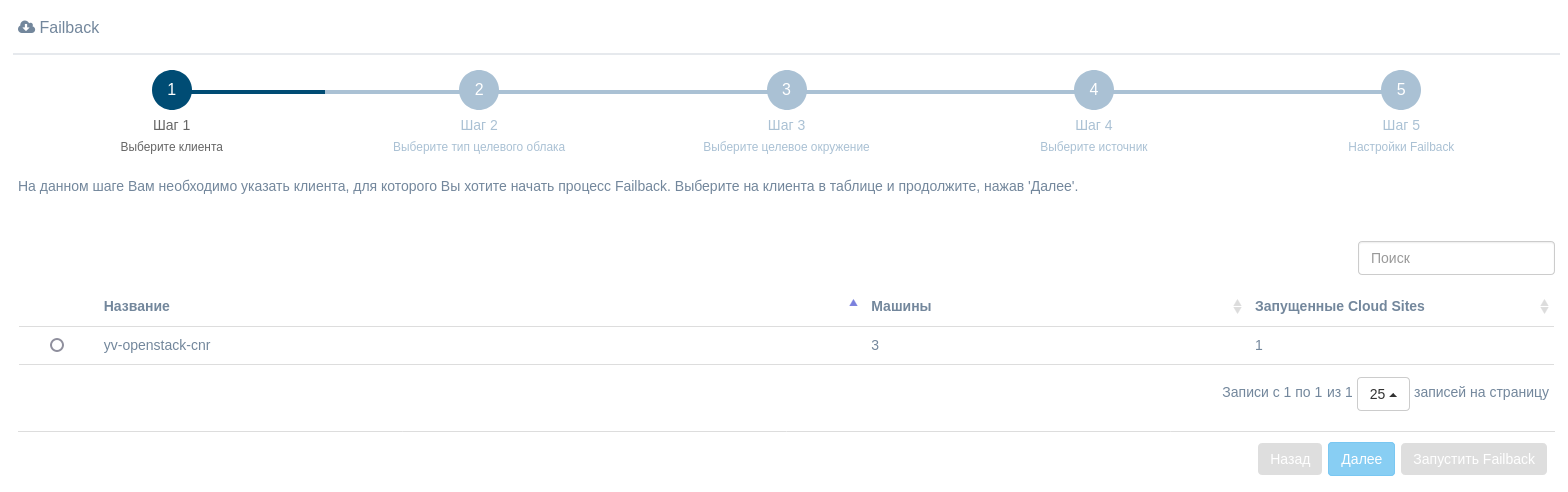
На втором шаге выберите облачную платформу и план восстановления, подходящий для восстановления ваших рабочих нагрузок - сценарий, описывающий машины, которые будут загружены и созданы.
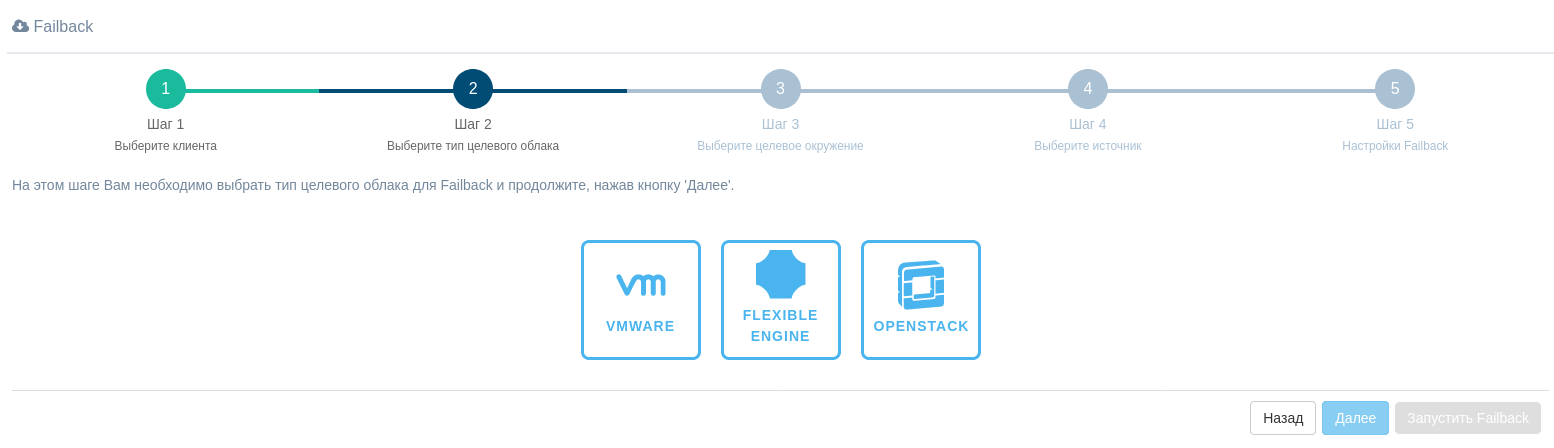
На третьем шаге выберите целевое облако для резервного копирования. Это поле является обязательным. Выберите существующую платформу или создайте новую и нажмите "Далее", чтобы продолжить.
В зависимости от выбранного типа failback будут отличаться параметры, необходимые для добавления нового облака.
Failback в VMware#
При регистрации нового облака для failback необходимо заполнить следующие поля:
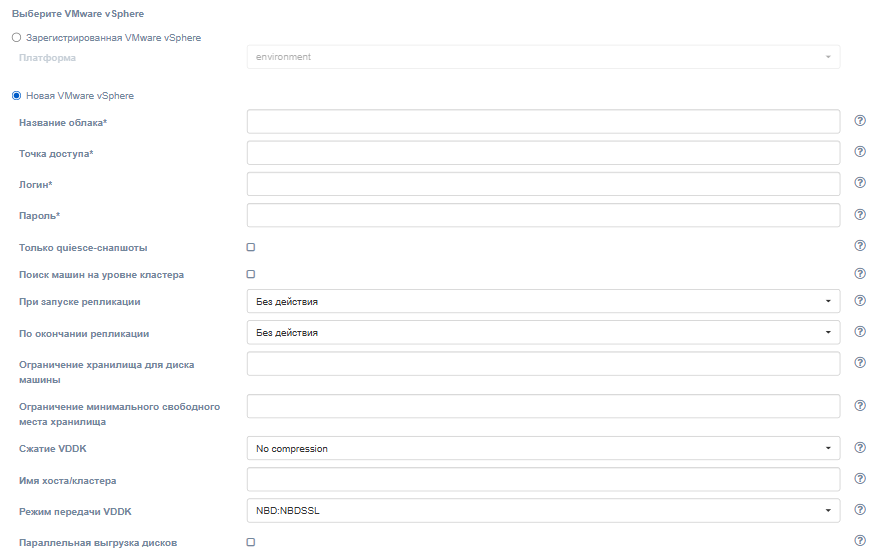
Note
Поля, c описанием «Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию», не влияют на настройку failback-агента. Оставьте их без изменений.
| Поле | Описание | Пример |
|---|---|---|
| Название облака | Название облака, которое будет отображаться в пользовательском интерфейсе. Название должно быть уникальным. | Failback cloud |
| Точка доступа | Точка доступа к облаку | 192.168.5.2 |
| Логин | Логин пользователя | user |
| Пароль | Пароль пользователя для доступа к целевому облаку | passw |
| Только quiesce-снапшоты | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | выключен |
| Поиск машин на уровне кластера | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | выключен |
| При запуске репликации | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | Без действия |
| По окончанию репликации | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | Без действия |
| Ограничение хранилища для диска машины | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | 0 или пусто |
| Ограничение минимального свободного места хранилища | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | 0 или пусто |
| Сжатие VDDK | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | No compression |
| Имя хоста/кластера | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | пусто |
| Режим передачи VDDK | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | NBD:NBDSSL |
| Параллельная выгрузка дисков | Не заполняйте; актуально только для агентов репликации. Оставьте по умолчанию. | выключен |
На четвёртом шаге выберите cloud site для failback и отказоустойчивые машины для процесса failback.
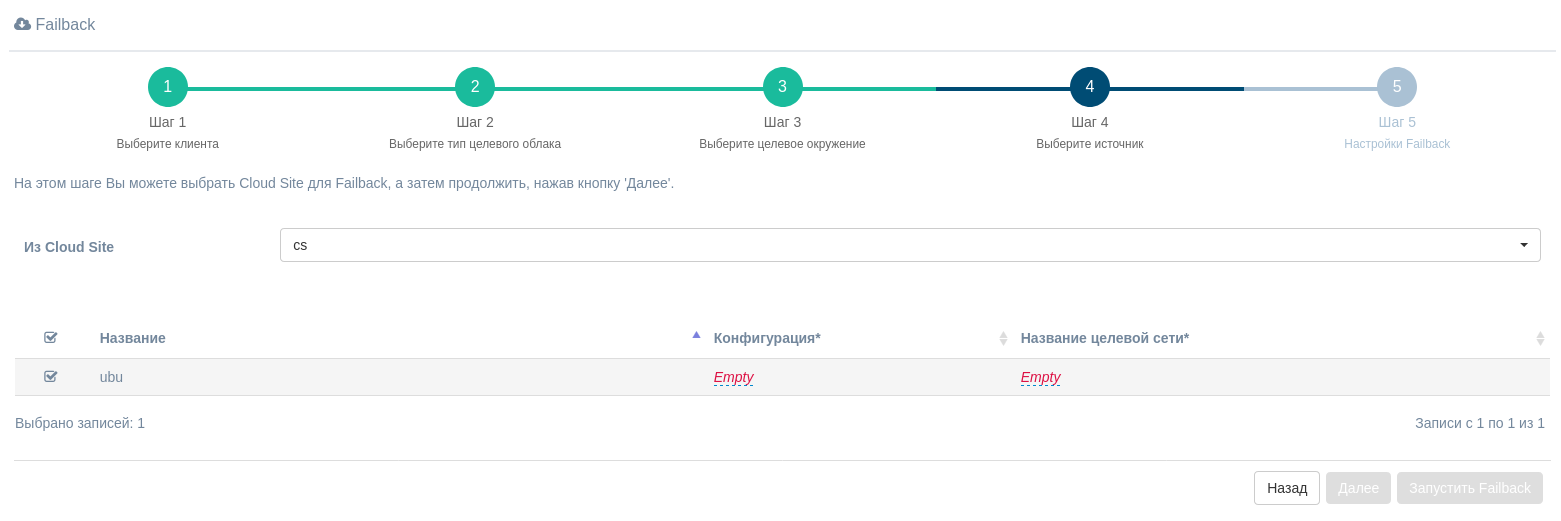
На пятом шаге используйте кнопку "Загрузка агента", чтобы получить агента. Агент, установленный в новой среде, необходим для загрузки данных с запущенного cloud site.
Повторно скачать файл агента можно на странице клиента Управление облаками.
После установки агента он будет отображаться как подключенный к сети, и можно будет указать целевое хранилище и хост для машины. Затем введите название failback и нажмите на кнопку "Запустить Failback".
Требования к failback-агенту VMware#
Порты для корректной работы агента:
- Связь с хостом Акуры - tcp/80, tcp/443
- Хост vSphere - tcp/443
- Хост(ы) ESXi - tcp/udp/902
- Отправка журналов в Акуре - udp/12201
В процессе failback используется тот же агент, что и для процесса репликации. Но, пожалуйста, обратите внимание, что существует ряд разрешений хоста, которые требуются агенту для успешного failback. Для ESXi версии 6.0 и старше список разрешений выглядит следующим образом:
- VirtualMachine.Inventory.Create
- VirtualMachine.Inventory.Delete
- VirtualMachine.Config.Rename
- VirtualMachine.Config.UpgradeVirtualHardware
- VirtualMachine.Configuration.Add New Disk
- VirtualMachine.Configuration.Raw Device
- Resource.Assign VirtualMachine to Resource Pool
- Datastore.Allocate Space
- Network.Assign Network
- VirtualMachine.Interact.PowerOn
- VirtualMachine.Interact.PowerOff
- VirtualMachine.Config.AdvancedConfig
- VirtualMachine.Provisioning.DiskRandomAccess
- VirtualMachine.Provisioning.DiskRandomRead
- VirtualMachine.State.Create Snapshot
- VirtualMachine.State.Revert Snapshot
- VirtualMachine.State.Remove Snapshot
- VirtualMachine.Configuration.CPUCount
- VirtualMachine.Configuration.Memory
- VirtualMachine.Config.AddRemoveDevice
- VirtualMachine.Config.Settings
Для ESXi 6.5 и выше создайте роль со следующими привилегиями:
-
- Datastore
-
- Allocate space
-
- Global
-
- Enable methods
-
- Network
-
- Assign network
-
- Resource
-
- Assign Virtual machine to resource pool
-
Virtual machine
-
- Change Configuration
-
- Acquire disk lease
-
- Add new disk
-
- Add or remove device
-
- Advanced configuration
-
- Configure Raw device
-
- Toggle disk change tracking
-
- Change CPU count
-
- Memory
-
- Edit Inventory
-
- Create from existing
-
- Create new
-
- Interaction
-
- Backup operation on virtual machine
-
- Power off
-
- Power on
-
- Provisioning
-
- Allow disk access
-
- Allow read-only disk access
-
- Allow virtual machine download
-
-
- Snapshot management
-
- Create snapshot
-
- Remove snapshot
-
- Revert to snapshot
Установка failback-агента VMware#
Разверните failback-агент на одном из хостов ESXi и запустите его. Войдите через терминал в учётную запись пользователя, которая была создана ранее во время загрузки агента.
Настраиваемые параметры плана DR для VMware#
Пример плана аварийного восстановления VMware:
{
"devices": {
"ubuntu-small": {
"id": "52560751-12ca-9b0e-db00-02cb718a138a",
"guest_id": "centos64Guest",
"hardware_ver": "vmx-11",
"flavor": "1-2",
"rank": 0,
"ports": [
{
"name": "port_0",
"mac": "de:ad:be:ef:15:89",
"subnet": "net"
}
]
}
},
"subnets": {
"net": {
"name": "net",
"subnet_id": "VM Network",
"cidr": "172.22.0.0/16"
}
}
}
При составлении плана восстановления пользователь может указать следующие пользовательские параметры: Идентификатор гостевой операционной системы и Версия оборудования. Соответствующими строками будут "guest_id" и "hardware_ver". Поскольку это внутренние параметры VMware, пожалуйста, обратитесь к их официальной документации для получения полного списка утвержденных типов и версий:
Failback в Flexible Engine#
Для регистрации нового облака failback необходимо заполнить следующие поля:
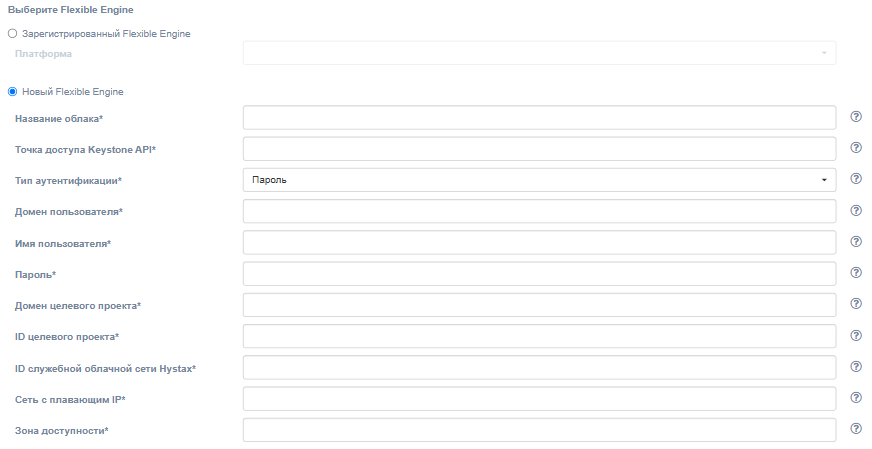
| Поле | Описание | Пример |
|---|---|---|
| Название облака | Название облака для отображения в пользовательском интерфейсе (должно быть уникальным). | Failback cloud |
| Keystone API endpoint | Аутентификационный URL Keystone | http://controller.example.com:35357/v3 |
| Тип аутентификации | Выберите тип аутентификации для Keystone API. | Пароль |
| Домен пользователя | Доменное имя пользователя для доступа к OpenStack | default |
| Имя пользователя | Имя пользователя для доступа к OpenStack | admin |
| Пароль | Пароль для доступа к OpenStack | passw |
| Домен целевого проекта | Целевой домен проекта OpenStack | default |
| ID целевого проекта | ID проекта, в котором будут размещены реплицируемые объекты | 39aa9af2e620404984f6d53a964386ef |
| ID служебного VPC Хайстекс | Идентификатор VPC, который будет использоваться для failback-машин Хайстекс | 6a61f859-ad2c-4092-826f-ee2ed85a3ec9 |
| Сеть с плавающим IP | Внешняя сеть, которая будет использоваться для подключения плавающих IP-адресов к перенесённым машинам | admin_external_net |
| Зона доступности | Зона доступности, в которой будут созданы все ресурсы | zone-1 |
Warning
В случае использования DVS, в качестве Endpoint рекомендуется использовать VCenter, не ESXi хост. Это связано с использованием сервиса метаданных VCenter.
Обратите внимание, что пользователь, использующийся для доступа, должен иметь необходимые права доступа для DVS.
На четвёртом шаге выберите cloud site и одну или несколько машин из выбранного cloud site, вы также можете определить конфигурацию, ID подсети и статический IP-адрес. Обратите внимание, что поле "ID подсети" является обязательным.
Следующий шаг - загрузить failback-агент, развернуть его в целевом облаке Flexible Engine и проверить конфигурацию failback. После этого введите название failback и нажмите на кнопку "Запустить Failback".
Повторно скачать файл агента можно на странице клиента Управление облаками.
Требования к failback-агенту Flexible Engine#
Порты для корректной работы агента:
- Связь с хостом Акуры - tcp/443
- Отправка журналов в Акуре - udp/12201
- Порты для связи с облачным API, например tcp/5000 для keystone
Установка failback-агента Flexible Engine#
Агент failback загружается как tar.gz файл с RAW-образом внутри. Извлеките данные из архива и создайте новый образ в целевом проекте из RAW-образа агента failback. Создайте новую ВМ из этого образа и запустите его.
Note
Для получения доступа к Акуры агенту failback требуется открыть порты tcp/443 и udp/12201.
Failback в OpenStack#
Для регистрации нового облака failback необходимо заполнить следующие поля:
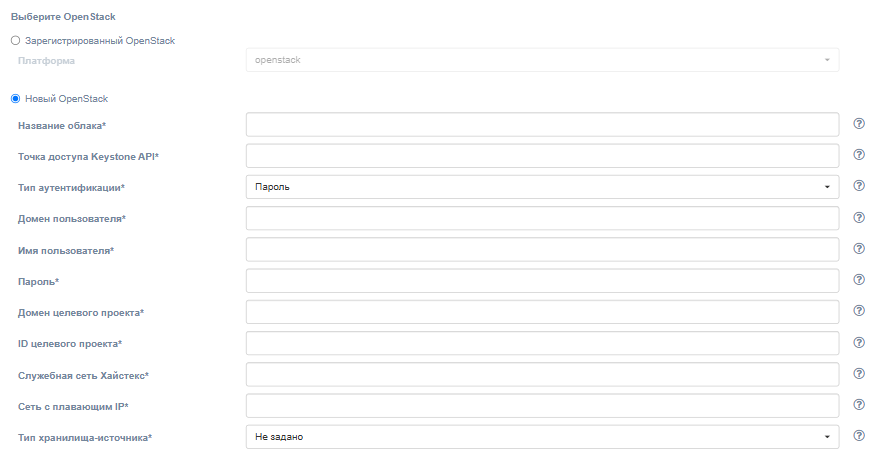
| Поле | Описание | Пример |
|---|---|---|
| Название облака | Название облака для отображения в пользовательском интерфейсе (должно быть уникальным). | Failback cloud |
| Keystone API endpoint | Аутентификационный URL Keystone | http://controller.example.com:35357/v3 |
| Тип аутентификации | Выберите тип аутентификации для Keystone API. | Пароль |
| Домен пользователя | Доменное имя пользователя для доступа к OpenStack | default |
| Имя пользователя | Имя пользователя для доступа к OpenStack | admin |
| Пароль | Пароль для доступа к OpenStack | passw |
| Домен целевого проекта | Целевой домен проекта OpenStack | default |
| ID целевого проекта | ID проекта, в котором будут размещены реплицируемые объекты | 39aa9af2e620404984f6d53a964386ef |
| Служебная сеть Хайстекс | Сеть, которая будет использоваться для failback-машин Хайстекс | provider |
| Сеть с плавающим IP | Внешняя сеть, которая будет использоваться для подключения плавающих IP-адресов к перенесённым машинам | admin_external_net |
| Тип хранилища-источника | Выберите хранилище для получения данных. Агент репликации для OpenStack требует задать хранилище, другие виды агентов настройки хранилища не требуют и не используют. | Не задано |
На четвёртом шаге выберите cloud site и одну или несколько машин из выбранного cloud site, вы также можете определить конфигурацию, ID подсети и статический IP-адрес. Обратите внимание, что поле "ID подсети" является обязательным.
Следующий шаг - загрузить агент failback, развернуть его в целевом облаке OpenStack и проверить конфигурацию failback. После этого введите название failback и нажмите на кнопку "Запустить Failback".
Повторно скачать файл агента можно на странице клиента Управление облаками.
Требования к failback-агенту OpenStack#
Порты для корректной работы агента:
- Связь с хостом Акуры - tcp/443
- Отправка журналов в Акуре - udp/12201
- Порты для связи с облачным API, например tcp/5000 для keystone
Установка failback-агента OpenStack#
Агент failback загружается как tar.gz файл с RAW-образом внутри. Извлеките данные из архива и создайте новый образ в целевом проекте из RAW-образа агента failback. Создайте новую ВМ из этого образа и запустите его.
Note
Для получения доступа к Акуры агенту failback требуется открыть порты tcp/443 и udp/12201.
Failback в другие облака#
Для других облаков failback выполняется в форме оперативной обратной миграции рабочих нагрузок в исходную среду. Внутренние агенты репликации устанавливаются непосредственно на отказоустойчивых машинах.
Все репликации выполняются в фоновом режиме и не требуют каких-либо простоев при failover до окончательного отключения. Вы можете запускать неограниченное количество тестовых failbacks/миграций.
Пожалуйста, свяжитесь с вашим поставщиком услуг или Хайстекс, чтобы получить инструменты для миграции.