Процесс восстановления#
Процесс восстановления состоит из следующих этапов: подготовка плана аварийного восстановления, настройка и запуск Cloud Site, проверка доступности и работоспособности сервисов на запущенных виртуальных машинах, при необходимости загрузка failover-образов виртуальных машин, Failback в продуктив, а также завершение работы и удаление Cloud Site.
Проводите регулярное тестирование Cloud Site, чтобы убедиться, что процессы восстановления действительно работают и соответствуют ожиданиям. Регулярное тестирование помогает выявить ошибки в конфигурации, сетевых настройках и зависимостях до возникновения реальной аварийной ситуации, а также повышают уверенность в доступности сервисов и соблюдении показателей RTO и RPO. В результате снижаются риски простоев и потери данных при реальном отказе.
Доступные сценарии восстановления#
-
Восстановление в виде виртуальной машины
Вариант использования: запуск виртуальной машины из определенной точки восстановления. Последовательность шагов:

-
Восстановление файлов и папок
Вариант использования: просмотр и загрузка файлов и папок из определенной точки восстановления. Подробная информация. Последовательность шагов:

-
Присоединение дисков
Варианты использования: восстановление файлов и папок с использованием уже существующей виртуальной машины, восстановление базы данных из журналов транзакций. Используйте вместе со сценарием "Восстановление в виде виртуальной машины" на уровне подключения дисков из дополнительной точки восстановления. Подробная информация. Последовательность шагов:

-
Загрузка образа из failover
Вариант использования: один из сценариев восстановления после сбоя — загрузка резервных дисков в виде образов RAW. Подробная информация. Последовательность шагов:

-
Failback
Вариант использования: автоматическое создание виртуальной машины на исходном сайте из виртуальной машины, восстановленной на целевой площадке, выполнение периодических инкрементных синхронизаций. Операция доступна для исходных облаков VMware, Flexible Engine и OpenStack, требуется загрузка и развертывание агента Failback. Подробная информация. Последовательность шагов:

-
Загрузка образа виртуальной машины
Вариант использования: восстановление виртуальной машины на исходном сайте из образов дисков точки восстановления. В целях безопасности/очистки загрузка образа имеет TTL. Подробная информация.
Планы аварийного восстановления#
Планы аварийного восстановления — это сценарии процесса восстановления, предназначенные на случай сбоя. Они включают в себя описание машин (количество vCPU, ОЗУ, ранг и т.д.) и сетей.
Создание плана аварийного восстановления#
Чтобы создать план аварийного восстановления, просто нажмите кнопку Добавить на странице клиента.
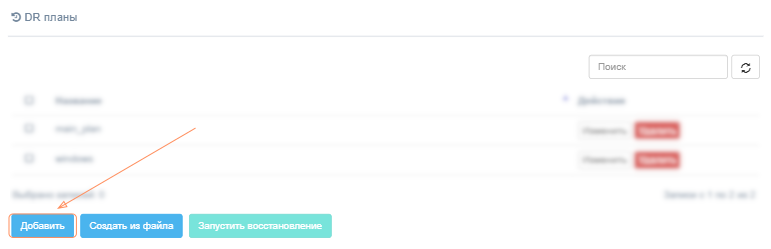
При добавлении нового плана укажите его название и содержимое плана. Название плана аварийного восстановления должно быть уникальным для клиента.
Существует два режима создания или редактирования плана: основной и расширенный. Чтобы переключаться между ними, выберите соответствующую вкладку на странице "Добавить DR план".
В основном режиме пользователь может либо вставить/ввести сетевые спецификации для отказоустойчивой машины вручную, либо выбрать сети из списка, который Акура получает непосредственно из целевого облака. Список сетей может быть получен автоматически со следующих платформ - VMware, OpenStack, Flexible Engine, AWS, Azure.
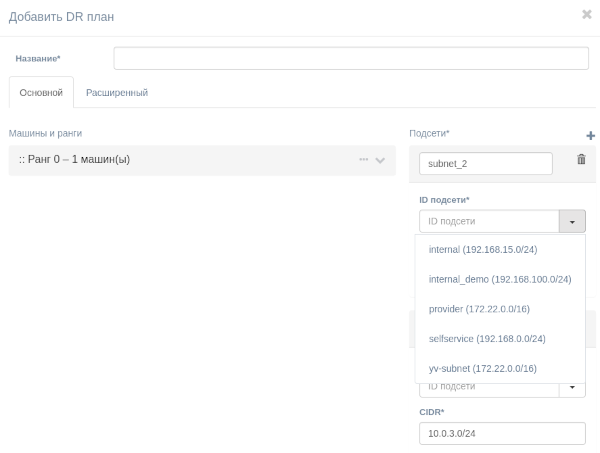
Расширенный режим позволяет указать более подробную конфигурацию в формате JSON.
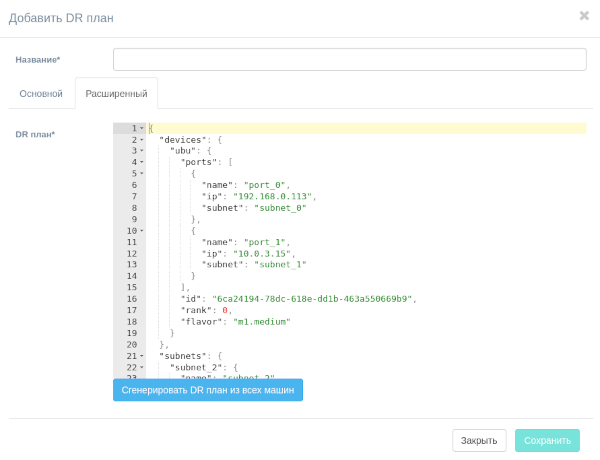
Основной частью плана аварийного восстановления является инструкция JSON для восстановления инфраструктуры и бизнес-приложения в DC.Чтобы сгенерировать план на основе всех клиентских машин, нажмите на Сгенерировать DR план из всех машин.
Создание плана аварийного восстановления для группы машин#
Можно создать план аварийного восстановления для отдельной машины, группы или на основе общих настроек. Чтобы создать план аварийного восстановления из группы машин для нескольких машин или групп, выберите нужные машины и нажмите кнопку Сгенерировать DR план в меню Групповые действия
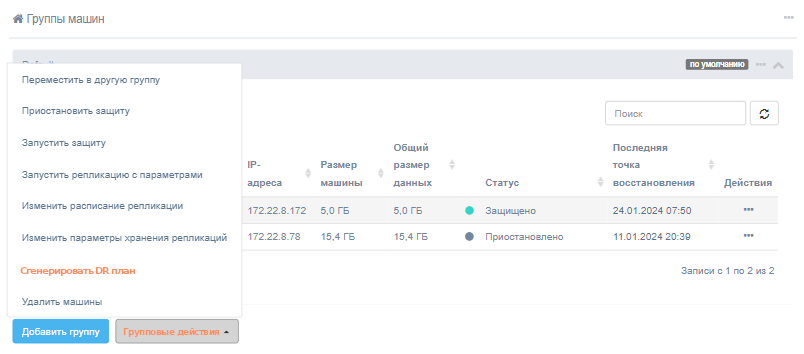
или в меню групп
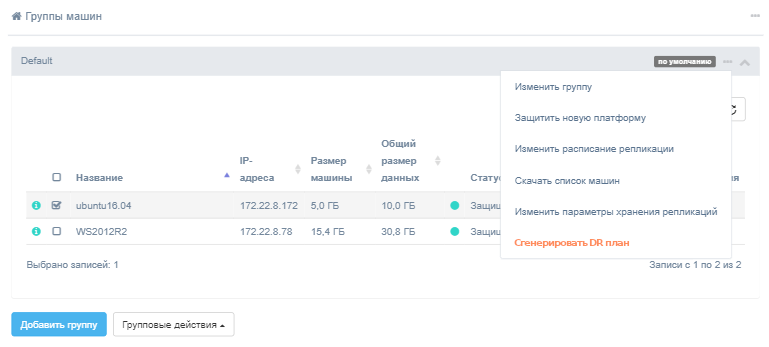
В результате появится диалоговое окно для создания и редактирования плана аварийного восстановления - дайте ему название. Название плана аварийного восстановления должно быть уникальным для клиента. Cодержимое плана будет сформировано на основании информации о выбранных машинах.
Создать план аварийного восстановления из файла#
Данный инструмент рекомендуется использовать для уже среплицированных машин. Особенно большую эффективность он показал на большом количестве машин, т.к. значительно экономит время создания плана. Скачайте список машин. В загруженном файле machines_list.csv ряд полей будет заполнен на основании данных репликации. Обновите информацию в поле flavor, впишите cidr сети, в котором должна подняться машина, добавьте информацию о портах, в колонки, начинающиеся с ports.
При готовности загрузите файл. Для запуска создания плана аварийного восстановления нажмите Применить.
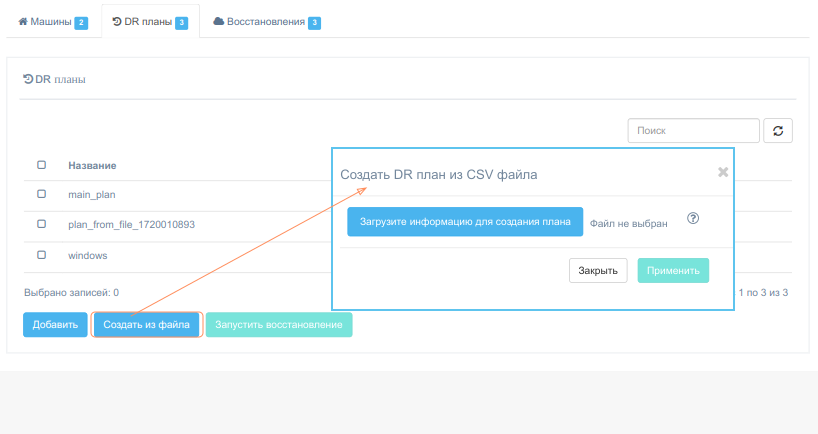
На создание плана аварийного восстановления потребуется некоторое время, после чего откроется окно. Отредактируйте название плана и другие поля, если нужно. Обратите особое внимание на предупреждающий текст оранжевого цвета в верхней части окна. Он показывает потенциально опасные места, из-за которых восстановление может отработать некорректно. Исправьте их на форме.
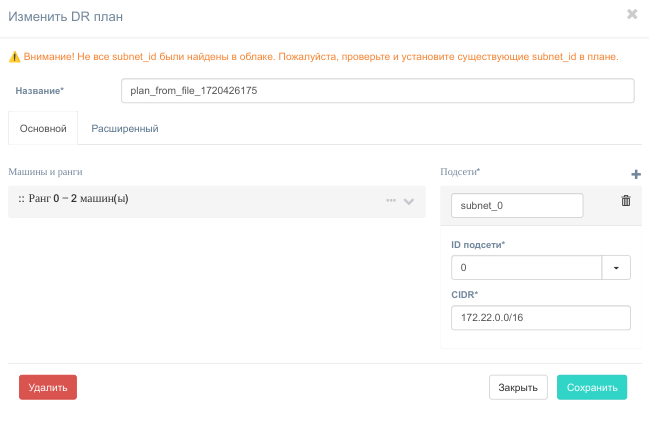
Сохраните план аварийного восстановления.
Синтаксис плана аварийного восстановления#
Основная часть плана аварийного восстановления представляет собой инструкцию JSON для восстановления инфраструктуры и бизнес-приложения в резервном DC.
Пример плана аварийного восстановления:
{
"devices": {
"IIS-Demo": {
"rank": 1,
"id": "52ce9361-b282-72b6-425a-f67347c5b79a",
"scheduler_hints": {
"group": "0c1b2901-7687-470e-a82c-6f69e92d5245"
},
"ports": [
{
"name": "port_0",
"ip": "192.168.15.112",
"subnet": "main_subnet"
},
{
"name": "port_1",
"subnet": "external"
}
]
},
"rhel7.2": {
"id": "522f3448-6a56-aa45-2131-207f7dda6664",
"ports": [
{
"name": "port_0",
"ip": "192.168.15.100",
"subnet": "main_subnet"
}
],
"rank": 0,
"boot_condition": {
"delay_seconds": 120,
"type": "wait"
}
}
},
"subnets": {
"main_subnet": {
"cidr": "192.168.15.0/24",
"subnet_id": "eda47a07-d1dd-4aca-ae8f-c652e997008e"
}
}
}
Базовые теги#
devices -- содержит описание каждой машины. Необходимо перечислить все машины, которые должны быть воссозданы в Cloud Site:
{
"devices": {
"rhel7.2": {
"id": "522f3448-6a56-aa45-2131-207f7dda6664",
"ports": {
"port_0": {
"ip": "192.168.15.100",
"subnet": "main_subnet"
},
"scheduler_hints": {
"group": "0c1b2901-7687-470e-a82c-6f69e92d5245"
}
},
"rank": 0,
"boot_condition": {
"delay_seconds": 120,
"type": "wait"
}
}
}
}
subnets -- содержит описание сетей, которые необходимо воссоздать в резервном DC:
{
"subnets": {
"main_subnet": {
"cidr": "192.168.15.0/24",
"subnet_id": "eda47a07-d1dd-4aca-ae8f-c652e997008e"
}
}
}
Синтаксис описания машины#
Описание машины состоит из ряда параметров, описывающих свойства машины, таких как название машины, сетевые настройки, ранг и условия загрузки машин для поддержания последовательности и согласованности процесса запуска Cloud Site.
{
"rhel7.2": {
"id": "522f3448-6a56-aa45-2131-207f7dda6664",
"custom_image_metadata": {
"hw_qemu_guest_agent": "no",
"os_require_quiesce": "no",
"my_os_type": "linux-custom",
"hw_disk_bus": "scsi",
"hw_scsi_model": "virtio-scsi",
"my_custom_image_tag": "linux"
},
"security_groups": [
"sg-1",
"sg-2"
],
"availability_zone": "zone-1",
"user_data": "#!/bin/bash\nrpm -e hlragent\nrm -rf /etc/hystax\n",
"ports": {
"port_0": {
"ip": "192.168.15.100",
"subnet": "main_subnet"
}
},
"rank": 0,
"scheduler_hints": {
"group": "0c1b2901-7687-470e-a82c-6f69e92d5245"
},
"boot_condition": {
"delay_seconds": 120,
"type": "wait"
}
}
}
Параметры описания машин:
| Параметр | Описание | Обязательность |
|---|---|---|
| machine_name | Базовый тег для описания машины. Имя будет использоваться для идентификации машины на cloud site. | Да |
| fix_dev_prefix | Введите префикс, если необходимо обновить названия дисков машины c ОС Linux во время P2V. Возможные значения: - ‘sd’ (для названий вида /dev/sda1), - ‘vd’ (для названий вида /dev/vda1), - ‘xvd’ (для названий вида /dev/xvda1). Названия дисков заменяются в рамках процесса P2V для Linux в следующих файлах (несуществующие файлы пропускаются): - /etc/fstab, - /boot/grub/grub.cfg (а также /grub/grub.cfg, если /boot – отдельный раздел), - /boot/grub2/grub.cfg (а также /grub2/grub.cfg, если boot – отдельный раздел). Например: { "devices": { "ds-debian10-sda": { "fix_dev_prefix": "vd", ... } } } |
Нет |
| id | Внутренний идентификатор машины (можно найти, наведя курсор мыши на название машины в списке машин на странице клиента). | Да |
| ports | Список конфигураций сетевых интерфейсов машины (может быть несколько). Интерфейсы будут добавлены в том же порядке, в котором они описаны. Описание параметров интерфейса и примера их использования приведено ниже. | Да |
| scheduler_hints | Дополнительные параметры планировщика при настройке отказоустойчивости. Параметр group позволяет указать группу серверов, в которой будут размещаться инстансы для отказоустойчивого запуска в OpenStack.Пример: "scheduler_hints": { "group": "0c1b2901-7687-470e-a82c-6f69e92d5245" } |
Нет |
| rank | Порядок, в котором будет запущена группа машин. Например, машины с рангом 2 будут запущены только после запуска всех машин с рангом 1, а те, в свою очередь, только после запуска всех машин с рангом 0. | Да |
| boot_condition | Состояние, в котором машина считается работающей. Поддерживается задержка во времени; по её истечении машина считается запущенной. Условие распространяется на весь ранг. Если есть несколько машин с задержкой по времени, ранг считается выполненным после ожидания в течение самого длительного времени. Синтаксис: "boot_condition": { "delay_seconds": number of seconds to wait, "type": "wait" } Пример: "boot_condition": { "delay_seconds": 120, "type": "wait" } |
Нет |
| flavor | Название или идентификатор существующей конфигурации в облаке. Для VMware и KubeVirt значение указывается как vCPU-RAM, например 2-4, что означает 2 vCPU и 4 ГБ. Пример: “flavor”: “2-4” |
Да |
| config_drive | По умолчанию – false. Установите в true, если хотите использовать конфигурационный диск. Пример: "config_drive": "true" |
Нет |
| security_groups | Список групп безопасности, которые будут использоваться для машины. Это приведёт к перезаписи группы (групп) по умолчанию. | Нет |
| availability_zone | Название зоны доступности, используемой для машины. Это приведёт к перезаписи зоны доступности, указанной в настройках облака. | Нет |
| user_data | Сценарий, который будет выполнен на целевой машине. Чтобы использовать ключ “user_data”, на исходной машине должен быть установлен cloud_init, в противном случае он будет проигнорирован. | Нет |
| firmware | Параметр, который выбирает вариант загрузки для машины (Vmware, oVirt, GCP). Доступные значения - BIOS (по умолчанию) или EFI. Пример: “firmware”: “EFI” |
Нет |
| guest_id | Идентификатор гостевой операционной системы. Обратитесь к официальной документации VMware. Пример: “guest_id”: “ubuntu64Guest”. |
Нет |
| hardware_ver | Аппаратная версия виртуальной машины. Обратитесь к официальной документации VMware. Пример: “hardware_ver”: “vmx-11”. |
Нет |
| byol (только для AWS) | Если byol - false (или не установлен), то используется AWS ImportImage (AWS запускает собственную P2V). Если byol - true, то используется AWS RegisterImage, и запускается наш собственный P2V. Пример: "devices": { "sd_small_ubuntu": { "rank": 0, "byol": true, } } |
Нет |
| ntp_server (только для Windows) | Протокол, используемый Windows для синхронизации. Пример: "devices": { "im-WS2019-ntp": { "flavor": "m1.medium", "ports": [ { "name": "port_0", "subnet": "provider-subnet" } ], "id": "52eef058-012b-70dd-9271-28ee5f56d171", "rank": 0, "ntp_server": "ntp6.ntp-servers.net" }, "subnets":{ "provider-subnet": { "name": "provider-subnet", "subnet_id": "6129317f-4987-4bf3-bfd0-c0edc3bc4bba", "cidr": "172.24.1.0/24" } } } |
Нет |
| hostname (только для Windows машин в облаке OpenStack) | Новое имя хоста Windows машины. Значение поля может принимать значения: - true (по умолчанию) – использовать имя машины из плана в качестве имени хоста - false – не менять имя хоста - любая строка – установить имя хоста как указано в строке. Пример: "devices": { "ds2012test": { "id": "9f51d0de-b6cb-400e-b223-5e748cc39d01", "flavor": "m1.medium", "hostname": "my-super-long-custom-hostname", "rank": 0, "ports": [ { "name": "port_0", "subnet": "DS-internal-2" } ] } }, "subnets": { "DS-internal-2": { "name": "DS-internal-2", "subnet_id": "76377dae-4e35-4183-bafa-b06eef69249e", "cidr": "172.22.0.0/16" } } |
Нет |
| rclocal_script | Сценарий, который запустится при загрузке Linux. Пример: "rclocal_script": "#!/bin/bash\ndate > date.txt\n" |
Нет |
| copy_efi_bootloader | По умолчанию – false. Установите в true, если хотите использовать загрузчик по умолчанию. Пример: "copy_efi_bootloader": true |
Нет |
| key_name | Ключ-пара для устройства. Пример: "key_name": "yv-key" |
Нет |
| meta | Список мета-тегов машины. Для OpenStack, OpenNebula. Пример: "devices": { "rhel7.2": { ... "meta": { "Image Name": "Hystax_CATI_...", "Image ID": "f389c03b-...", "Image": "image", "Key Name": "username" } } |
Нет |
| custom_image_metadata | Задать пользовательские метаданные образа для среплицированных ВМ. Только OpenStack. Пример: "custom_image_metadata": { "hw_qemu_guest_agent": "no", "os_require_quiesce": "no", "my_os_type": "linux-custom", "hw_disk_bus": "scsi", "hw_scsi_model": "virtio-scsi", "my_custom_image_tag": "linux" }, Параметр можно задать как строку с объектом JSON: "custom_image_metadata": "hw_qemu_guest_agent=no,os_require_quiesce=no,my_os_type=linux-custom,hw_disk_bus=scsi,hw_scsi_model=virtio-scsi,yv_custom_image_tag=Linux". Также этот параметр можно задать как дополнительную опцию на этапе “Установки и начальной настройки решения” или при добавлении облака. Обратите внимание, что, если параметр задан и на этапе начальной конфигурации/добавления облака, и в DR плане, то к облаку будут применены настройки DR плана, т.к имеют приоритет выше, даже если значение представляет собой пустую строку. |
Нет |
Описание интерфейса ports имеет следующие параметры:
| Параметр | Описание | Обязательность |
|---|---|---|
| name | Название интерфейса | Да |
| ip | IP-адрес интерфейса. По умолчанию адаптеры Windows будут настроены как DHCP. Если вы хотите установить статические настройки, то используйте это поле совместно с mac. |
Нет |
| mac | MAC-адрес интерфейса. Игнорируется для облака AWS. | Нет |
| subnet | Название подсети интерфейса | Да |
| routing_allowed | Позволяет машине быть маршрутизатором (может быть “true” или “false” (по умолчанию)). Игнорируется для облака AWS. | Нет |
| floating_ip | добавляет floating_ip для порта (может быть “true” или “false” (по умолчанию)). Использование этого параметра со значением “true” ограничивает устройство наличием только одного порта. “floating_ip”: “ |
Нет |
| mtu (только для Windows) | Наибольший размер пакета, отправляемый по сети без фрагментации. Используйте этот параметр в паре с параметром mac. Пример: "devices": { "DS2012R2MULMBR": { "id": "9f51d0de-b6cb-400e-b223-5e748cc39d01", "flavor": "m1.medium", "rank": 0, "ports": [ { "name": "port_0", "ip": "172.22.8.249", "mac": "08:00:27:46:79:29", "gateway_ip": "172.22.1.2", "dns_nameservers": [ "172.22.1.2", "8.8.4.4" ], "mtu": 1511, "subnet": "DS-internal-2" } ] } }, "subnets": { "DS-internal-2": { "name": "DS-internal-2", "subnet_id": "76377dae-4e35-4183-bafa-b06eef69249e", "cidr": "172.22.0.0/16" } } |
Нет |
Примеры:
"ports": [
{
"name": "port_0",
"ip": "192.168.15.100",
"subnet": "main_subnet"
}
]
Порты, подсети, mac, ip, gateway и dns. Используйте mac, чтобы установить статический ip:
{
"devices": {
"sd_small_ubuntu": {
"rank": 0,
"ports": [
{
"name": "port_0",
"ip": "172.22.8.144",
"mac": "08:00:27:46:79:27",
"gateway_ip": "172.22.1.2",
"dns_nameservers": [
"172.22.1.2",
"172.22.1.3"
],
"subnet": "subnet_1"
}
],
"id": "5260881c-c921-f037-df78-6105f018a9c2",
"flavor": "m1.medium"
}
},
"subnets": {
"subnet_1": {
"name": "subnet_1",
"cidr": "172.22.0.0/16"
}
}
}
Пример для случая, если IP динамический:
{
"devices": {
"centos": {
"ports": [
{
"name": "port_0",
"floating_ip": true,
"subnet": "subnet_0"
}
]
<...>
}
}
}
Синтаксис описания сети#
Описание сети состоит из ряда параметров, таких как название сети, её CIDR и адреса DNS-серверов.
Пример:
{
"subnets": {
"main_subnet": {
"cidr": "192.168.15.0/24",
"subnet_id": "eda47a07-d1dd-4aca-ae8f-c652e997008e"
}
}
}
Параметры описания сети:
| Параметр | Описание | Обязательность |
|---|---|---|
| network name | Название сетевого идентификатора является базовым тегом для описания сети | Да |
| cidr | CIDR сети | Да |
| subnet_id | Существующий идентификатор подсети в целевом облаке | Да |
Warning
Указанный идентификатор подсети должен быть доступен для используемой зоны доступности.
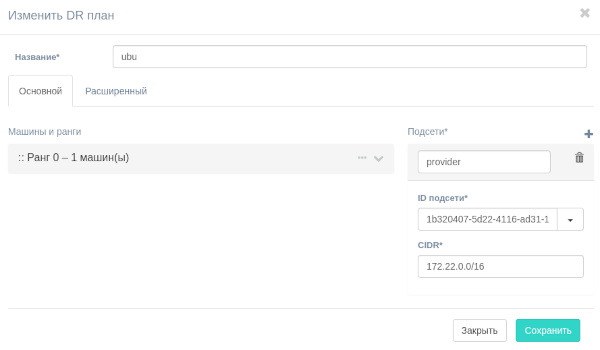
Редактирование существующего плана аварийного восстановления#
Чтобы отредактировать существующий план аварийного восстановления, нажмите кнопку Изменить напротив этого плана на странице клиента.
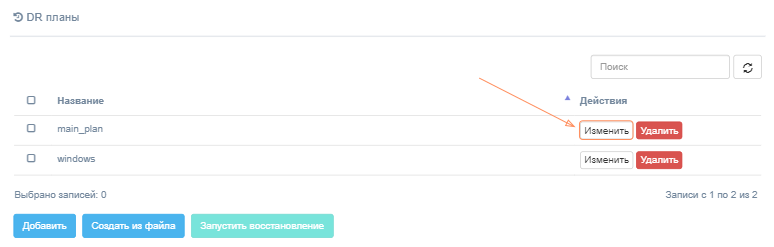
Появится диалоговое окно, в котором можно отредактировать план аварийного восстановления.
Подготовка к сбою. Тестирование планов аварийного восстановления#
Чтобы заранее подготовиться к сбою и свести к минимуму связанные с этим проблемы, мы рекомендуем не реже, чем один раз в 3-4 недели проводить тестирование. Для этого:
- Создайте или обновите план аварийного восстановления.
- Создайте или обновите набор тестов для проверки работоспособности восстановленных тестовых ВМ. Обратите внимание, что этот набор тестов должен быть подготовлен как часть стратегии аварийного восстановления и адаптирован к инфраструктуре заказчика; заказчик и поставщик услуг аварийного восстановления несут взаимную ответственность за их подготовку.
-
Запустите процесс создания Cloud Site. Есть несколько способов выберите более удобный:
- через кнопку Запустить на вкладке с планами восстановления,
- через кнопку Восстановить в левом меню.
Подробнее в статье Создание Cloud Site.
-
Запустите набор тестов, подготовленных в пункте 2, на машинах работающего Cloud Site.
- Удалите Cloud Site.
- Обновите план аварийного восстановления (например, добавьте описания новых машин или удалите устаревшие) и набор тестов при необходимости. Повторите пункты 3-6.
Восстановление во время аварии#
Во время восстановления при аварии важно не только поддерживать доступность и минимизировать потерю данных, но и восстановить сервисы как можно быстрее. Рекомендуем выполнить следующий набор шагов:
1. Создайте Cloud Site. На втором шаге мастера создайте пользовательский план, если существующие планы не обновлялись некоторое время и нет возможности оперативно привести их в соответствие с последними изменениями.
Note
Процесс восстановления требует времени. Его продолжительность зависит от сложности структуры плана аварийного восстановления и уровней согласованности/зависимости между компонентами бизнес-приложения. Как только все компоненты получат статус Активен, бизнес-приложение готово к работе, и можно переходить к следующему этапу.
2. Выполните упрощённый набор тестов на Cloud Site, прежде чем переключать производственный трафик.
3. Перенесите основной трафика на Cloud Site и настройте отдельные компоненты.
Warning
Перенаправление основного трафика на резервный сайт не является частью текущей функциональности решения и должно быть заранее согласовано с поставщиком услуг.
4. Выполните Failback в продуктив.
5. Удалите Cloud Site.
Failback в продуктив#
Failback — это процесс возврата работы системы или бизнес-приложения с резервной (аварийной) площадки обратно на основной сайт после устранения сбоя.
Процедура выполняется поэтапно и включает следующие шаги:
1. Для Failback используется Cloud Site. Подробнее о запуске Cloud Site.
2. Cкачайте агент Failback и разверните его на площадке, куда планируется
возврат.
3. Запустите процесс Failback. В нашем приложении поддерживается Failback для трех типов облаков: VMware, Flexible Engine и OpenStack. Для остальных облаков используйте процедуру обратной миграции.
4. После завершения синхронизации выполните запуск машин в
продуктивной среде и перенаправьте пользовательский трафик.
5. Настройте защиту нового продуктива, обеспечив актуальные механизмы
резервного копирования и аварийного восстановления.
Как только эти шаги будут выполнены, бизнес-приложение вернётся к работе со всеми изменениями, накопленными с момента перенаправления трафика на резервный сайт.
Failback в VMware#
Требования к Failback-агенту VMware#
Порты для корректной работы агента:
- Связь с хостом Акуры - исходящий tcp/443
- Хост vSphere - исходящий tcp/443
- Хост(ы) ESXi - исходящий tcp/udp/902
- Отправка журналов в Акуру - исходящий udp/12201
Обратите внимание, что существует ряд разрешений хоста, которые требуются агенту для успешного Failback. Для ESXi версий 6.0 - 6.5 список разрешений выглядит следующим образом:
- VirtualMachine.Inventory.Create
- VirtualMachine.Inventory.Delete
- VirtualMachine.Config.Rename
- VirtualMachine.Config.UpgradeVirtualHardware
- VirtualMachine.Configuration.Add New Disk
- VirtualMachine.Configuration.Raw Device
- Resource.Assign VirtualMachine to Resource Pool
- Datastore.Allocate Space
- Network.Assign Network
- VirtualMachine.Interact.PowerOn
- VirtualMachine.Interact.PowerOff
- VirtualMachine.Config.AdvancedConfig
- VirtualMachine.Provisioning.DiskRandomAccess
- VirtualMachine.Provisioning.DiskRandomRead
- VirtualMachine.State.Create Snapshot
- VirtualMachine.State.Revert Snapshot
- VirtualMachine.State.Remove Snapshot
- VirtualMachine.Configuration.CPUCount
- VirtualMachine.Configuration.Memory
- VirtualMachine.Config.AddRemoveDevice
- VirtualMachine.Config.Settings
Для ESXi 6.5 и выше создайте роль со следующими привилегиями:
-
Datastore → Allocate space
-
Global → Enable methods
-
Network → Assign network
-
Resource → Assign Virtual machine to resource pool
-
Virtual machine → Change Configuration
- Acquire disk lease
- Add new disk
- Add or remove device
- Advanced configuration
- Configure Raw device
- Toggle disk change tracking
- Change CPU count
- Memory
-
Virtual machine → Edit Inventory
- Create from existing
- Create new
-
Virtual machine → Interaction
- Backup operation on virtual machine
- Power off
- Power on
-
Virtual machine → Provisioning
- Allow disk access
- Allow read-only disk access
- Allow virtual machine download
-
Snapshot management
- Create snapshot
- Remove snapshot
- Revert to snapshot
Установка Failback-агента VMware#
Для того, чтобы операция Failback прошла успешно, предварительно скачайте и разверните Failback-агент: перейдите на страницу клиента → Управление облаками. В случае, если переезд происходит на новое облако добавьте его. Далее откройте Действия и выберите пункт меню Загрузка агента Failback. Следуйте инструкции по развертыванию агента:
- Скачайте OVA-файл и установите его на каждый из ESXi-хостов в VMware кластере, на котором Вы хотите воссоздать виртуальные машины.
- Запустите виртуальные машины (агенты) из OVA-файла на каждом из ESXi-хостов. Это необходимо для загрузки данных с запущенного Cloud Site.
Через несколько минут после установки и запуска агентов ESXi-хосты появятся в списке доступных. Используйте их для воссоздания виртуальных машин при операции Failback. Обновите хранилище дисков для каждой машины в соответствии с выбранным хостом.
Операция Failback для VMware#
Чтобы запустить Failback, нажмите на пункт меню Failback на левой боковой панели.
Failback включает в себя пять (для партнёра) или четыре (для клиента) шага.
Рассмотрим последовательность для партнера.
Шаг 1. Выберите клиента
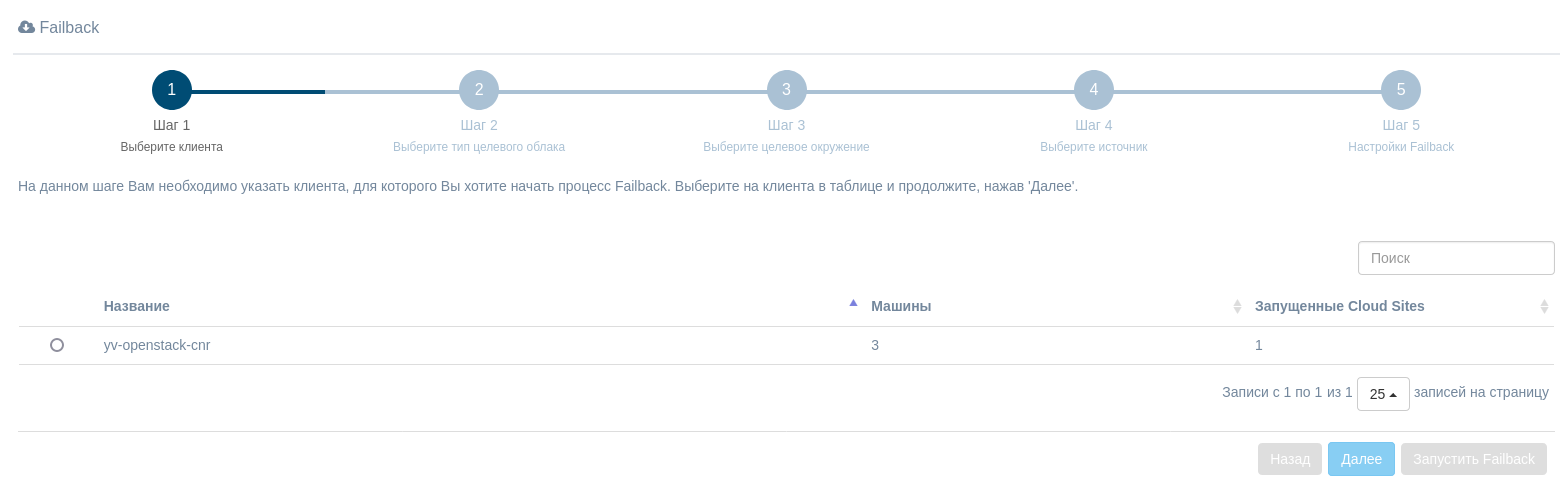
Шаг 2. Выберите тип целевого облака
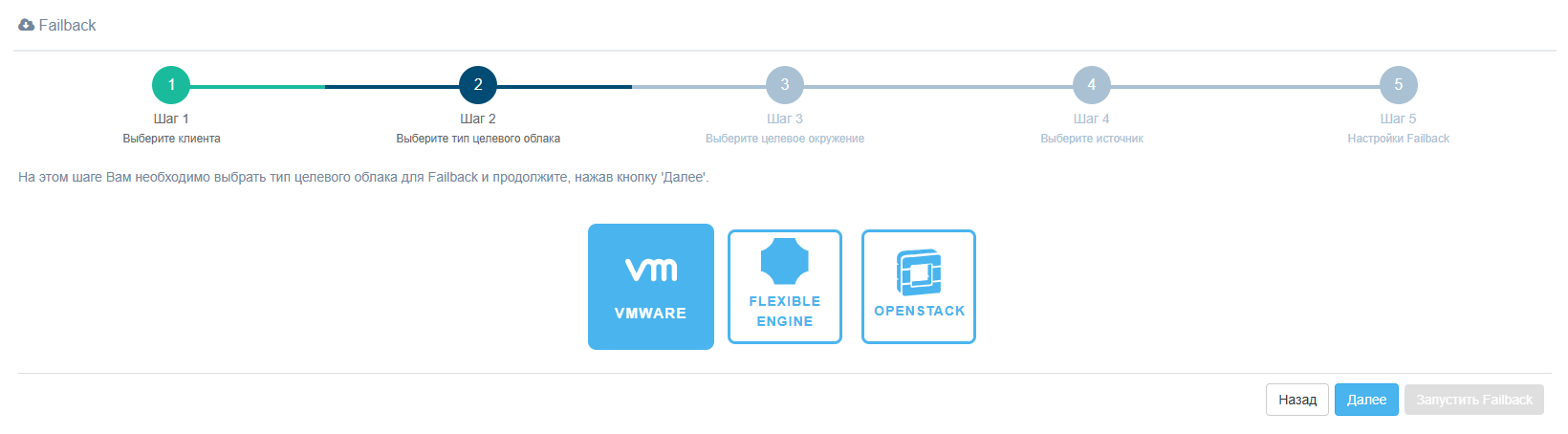
Шаг 3. Выберите целевое окружение
Выберите уже зарегистрированную VMware vSphere из списка или добавьте новую.
Note
В данной инструкции мы приводим последовательность действий в случае, если в процессе Failback вы захотите настроить новое облако. Однако, рекомендуем делать это заранее, до запуска Failback.
При регистрации нового облака достаточно заполнить только четыре поля:
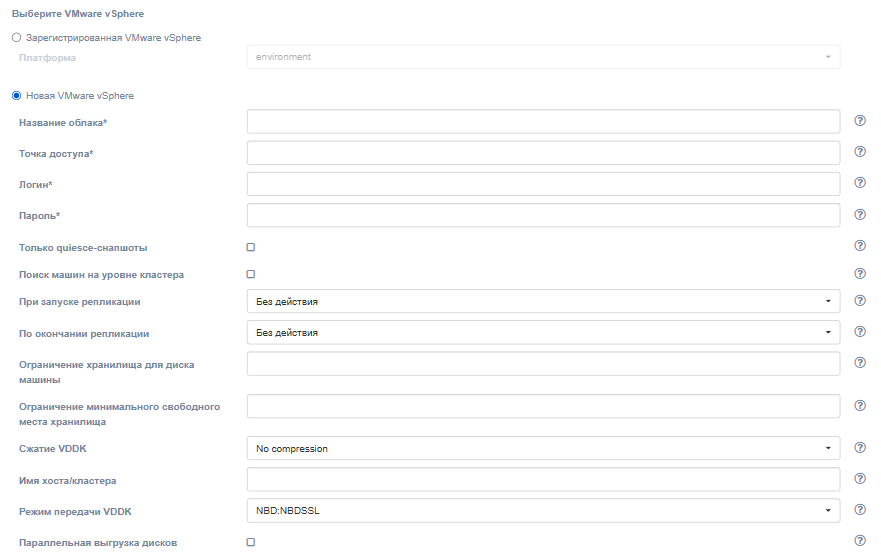
Note
Оставшиеся поля не влияют на настройку Failback-агента. Оставьте их без изменений.
| Поле | Описание | Пример |
|---|---|---|
| Название облака | Название облака, которое будет отображаться в пользовательском интерфейсе. Название должно быть уникальным. | Failback cloud |
| Точка доступа | Точка доступа к облаку | 192.168.5.2 |
| Логин | Логин пользователя | user |
| Пароль | Пароль пользователя для доступа к целевому облаку | passw |
Warning
В случае использования DVS, в качестве Endpoint рекомендуется использовать vCenter, не ESXi хост. Это связано с использованием сервиса метаданных vCenter.
Обратите внимание, что пользователь, использующийся для доступа, должен иметь необходимые права доступа для DVS.
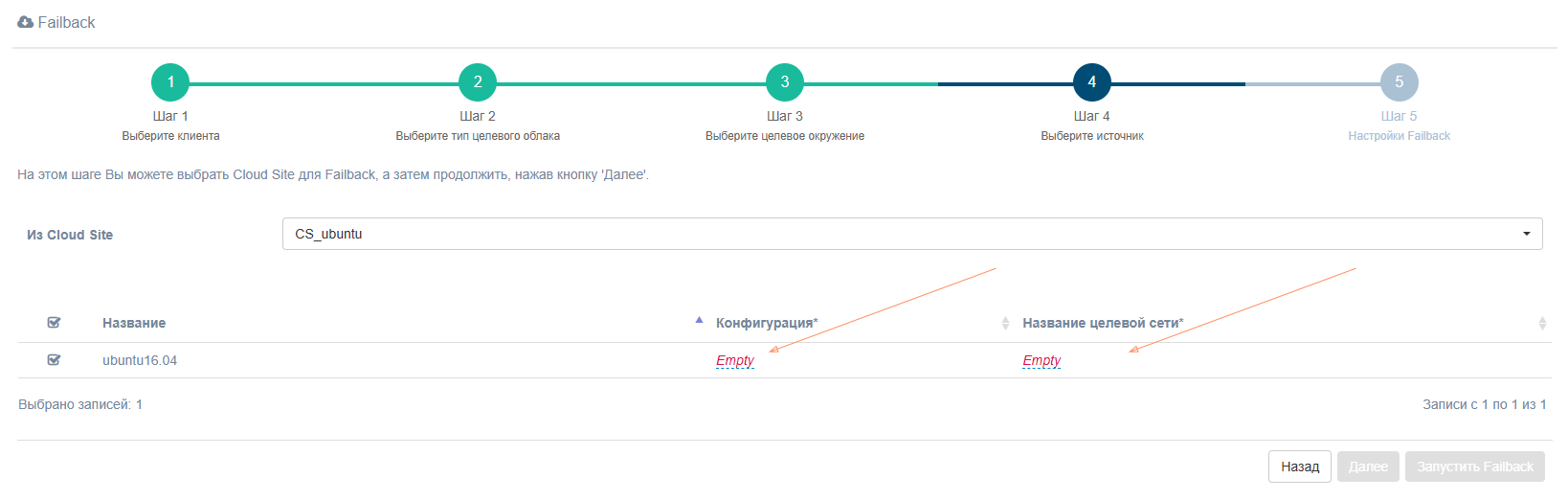
Шаг 4. Выберите источник
Выберите Cloud Site и машины для процесса Failback, заполните поля Конфигурация и Название целевой сети. После заполнения всех полей кнопка Далее становится активной.
Шаг 5. Настройки Failback
Задайте название для Failback. Поля Оперативная память и Ядер процессора заполняются автоматически на основании параметров, введенных на четвертом шаге. Выберите из списка Название целевого ESXi хоста и Целевое хранилище. Списки формируются на основании данных, полученных от Failback-агента, поэтому важно установить его заранее.
Note
В случае, если Failback-агент не был установлен предварительно, при переходе на пятый шаг скачайте его и разверните на его основании машину. Не запускайте Failback пока агент не будет установлен!
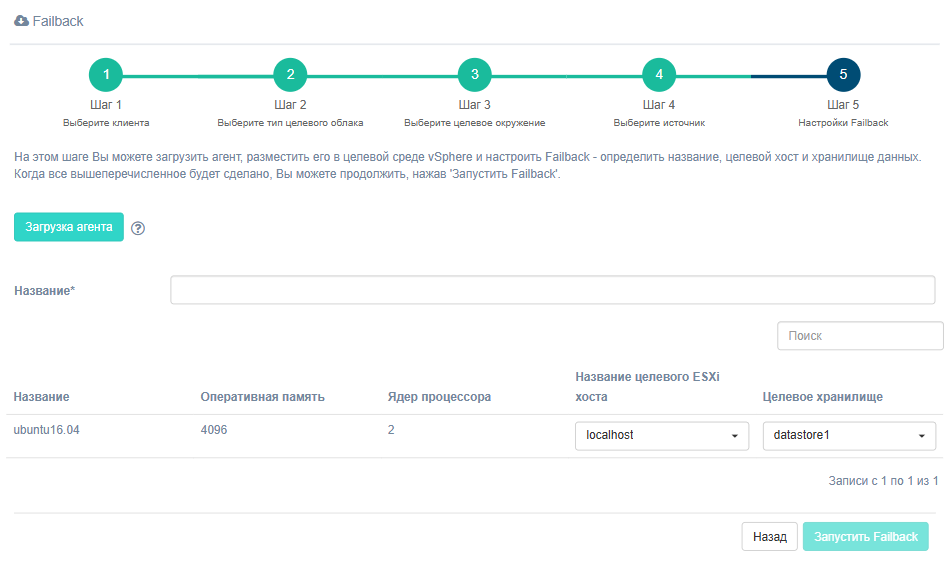
Кнопка Запустить Failback станет активной, когда все данные введены.
Настраиваемые параметры Failback-плана для VMware#
Для облака VMware есть возможность передать параметры для Failback через API.
Пример Failback-плана:
{
"devices": {
"ubuntu-small": {
"id": "52560751-12ca-9b0e-db00-02cb718a138a",
"guest_id": "centos64Guest",
"hardware_ver": "vmx-11",
"flavor": "1-2",
"rank": 0,
"ports": [
{
"name": "port_0",
"mac": "de:ad:be:ef:15:89",
"subnet": "net"
}
]
}
},
"subnets": {
"net": {
"name": "net",
"subnet_id": "VM Network",
"cidr": "172.22.0.0/16"
}
}
}
При составлении плана восстановления пользователь может указать следующие пользовательские параметры: Идентификатор гостевой операционной системы и Версия оборудования. Соответствующими строками будут "guest_id" и "hardware_ver". Поскольку это внутренние параметры VMware, пожалуйста, обратитесь к их официальной документации для получения полного списка утвержденных типов и версий.
Failback в Flexible Engine#
Требования к Failback-агенту Flexible Engine#
Порты для корректной работы агента:
- Связь с хостом Акуры - исходящий tcp/443
- Отправка журналов в Акуру - исходящий udp/12201
- Порты для связи с облачным API, например, tcp/5000 для keystone
Установка Failback-агента Flexible Engine#
Для того, чтобы операция Failback прошла успешно, предварительно скачайте и разверните Failback-агент: перейдите на страницу клиента → Управление облаками. В случае, если переезд происходит на новое облако добавьте его. Далее откройте Действия и выберите пункт меню Загрузка агента Failback. Следуйте инструкции по развертыванию агента:
- Скачайте RAW-файл агента Failback и создайте из него новый образ в целевом проекте.
- Создайте новую ВМ из этого образа и запустите её.
Note
Для получения доступа к Акуре откройте агенту Failback порты tcp/443 и udp/12201.
Процедура Failback для Flexible Engine#
Чтобы запустить Failback, нажмите на пункт меню Failback на левой боковой панели.
Failback включает в себя пять (для партнёра) или четыре (для клиента) шага.
Рассмотрим последовательность для партнера.
Шаг 1. Выберите клиента
Шаг 2. Выберите тип целевого облака
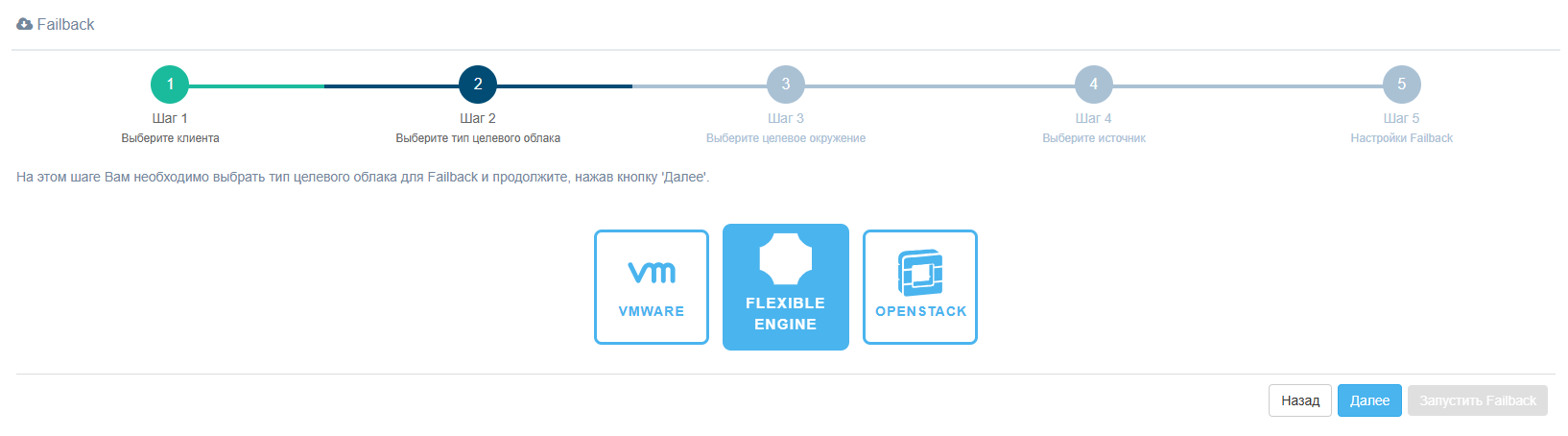
Шаг 3. Выберите целевое окружение
Выберите уже зарегистрированную Flexible Engine из списка или добавьте новую.
Note
В данной инструкции мы приводим последовательность действий в случае, если в процессе Failback вы захотите настроить новое облако. Однако, рекомендуем делать это заранее, до запуска Failback.
Для регистрации нового облака Failback необходимо заполнить следующие поля:
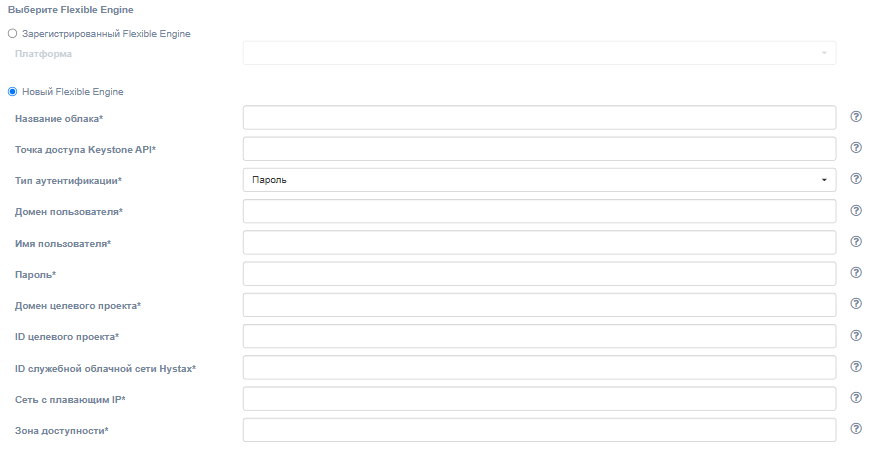
| Поле | Описание | Пример |
|---|---|---|
| Название облака | Название облака для отображения в пользовательском интерфейсе (должно быть уникальным). | Failback cloud |
| Keystone API endpoint | Аутентификационный URL Keystone | http://controller.example.com:35357/v3 |
| Тип аутентификации | Выберите тип аутентификации для Keystone API. | Пароль |
| Домен пользователя | Доменное имя пользователя для доступа к OpenStack | default |
| Имя пользователя | Имя пользователя для доступа к OpenStack | admin |
| Пароль | Пароль для доступа к OpenStack | passw |
| Домен целевого проекта | Целевой домен проекта OpenStack | default |
| ID целевого проекта | ID проекта, в котором будут размещены реплицируемые объекты | 39aa9af2e620404984f6d53a964386ef |
| ID служебного VPC Хайстекс | Идентификатор VPC, который будет использоваться для failback-машин Хайстекс | 6a61f859-ad2c-4092-826f-ee2ed85a3ec9 |
| Сеть с плавающим IP | Внешняя сеть, которая будет использоваться для подключения плавающих IP-адресов к перенесённым машинам | admin_external_net |
| Зона доступности | Зона доступности, в которой будут созданы все ресурсы | zone-1 |
Шаг 4. Выберите источник
Выберите Cloud Site и машины для процесса Failback, определите конфигурацию, ID подсети, а также ID инстанса Failback и статический IP-адрес. Обратите внимание, что поля Конфигурация и ID подсети являются обязательными.
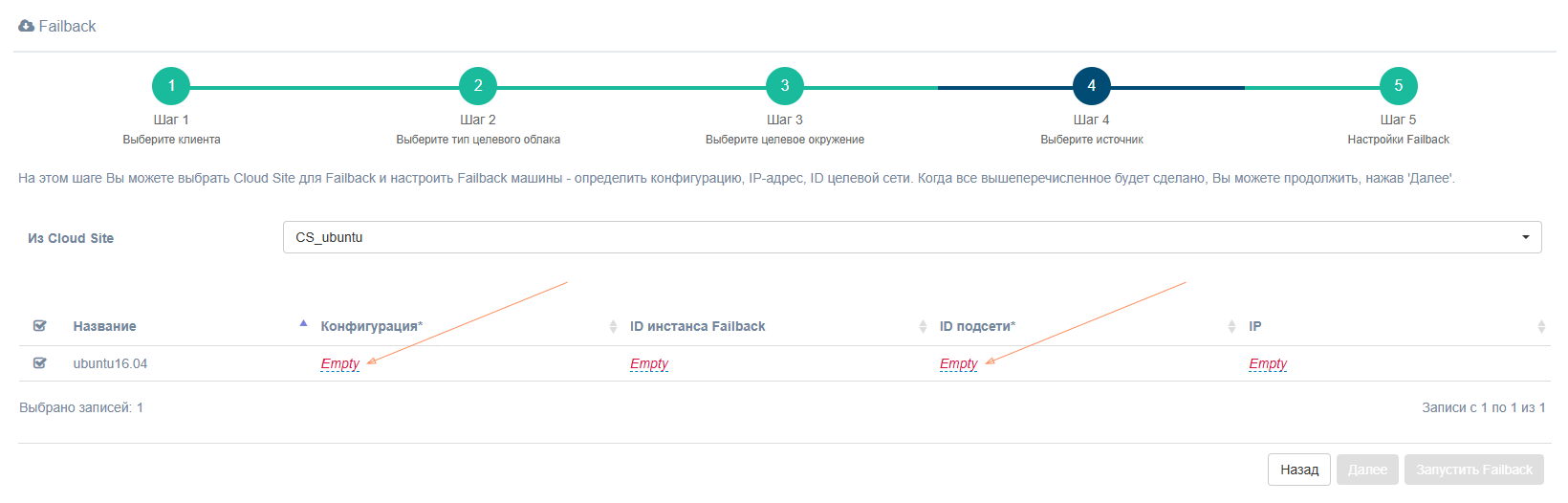
Шаг 5. Настройки Failback
Note
В случае, если Failback-агент не был установлен предварительно, при переходе на пятый шаг его нужно обязательно скачать и развернуть на его основании машину. Не запускайте Failback пока агент не будет установлен!
Задайте название для Failback.
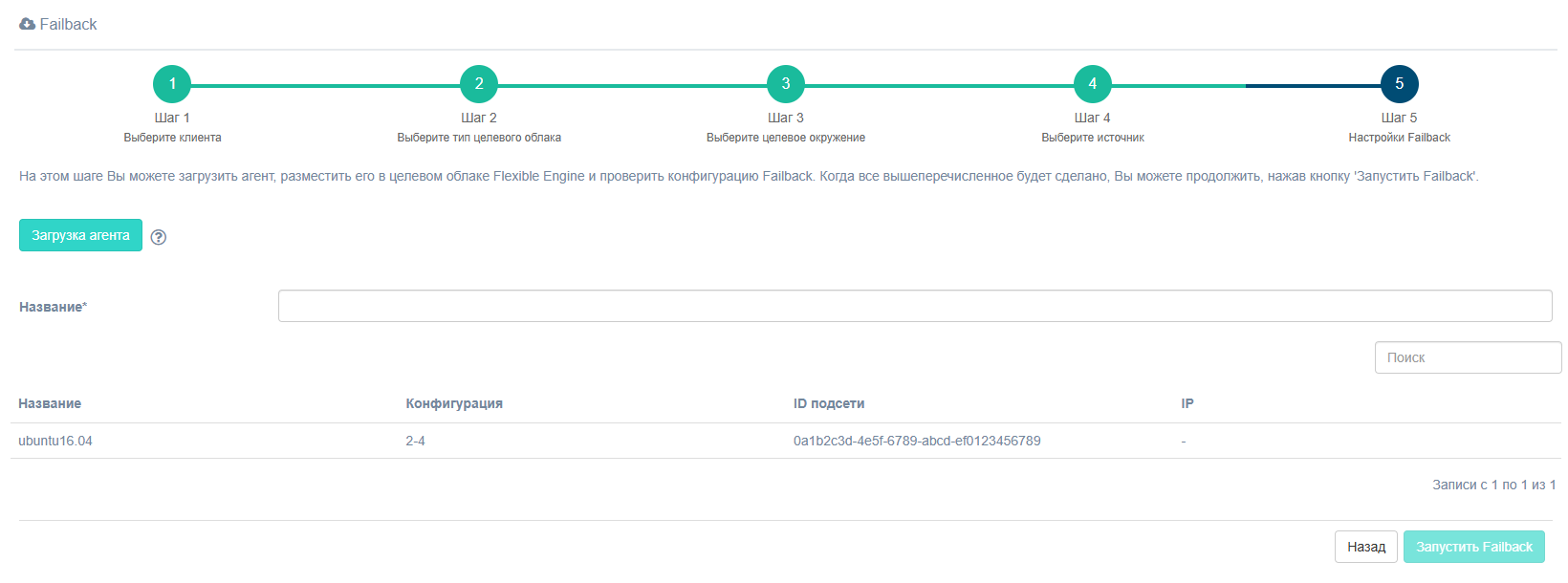
Кнопка Запустить Failback станет активной, когда все данные введены.
Failback в OpenStack#
Требования к Failback-агенту OpenStack#
Порты для корректной работы агента:
- Связь с хостом Акуры - исходящий tcp/443
- Отправка журналов в Акуру - исходящий udp/12201
- Порты для связи с облачным API, например, tcp/5000 для keystone
Установка Failback-агента OpenStack#
Для того, чтобы операция Failback прошла успешно, предварительно скачайте и разверните Failback-агент: перейдите на страницу клиента → Управление облаками. В случае, если переезд происходит на новое облако добавьте его. Далее откройте Действия и выберите пункт меню Загрузка агента Failback. Следуйте инструкции по развертыванию агента:
- Скачайте RAW-файл агента Failback и создайте из него новый образ в целевом проекте.
- Создайте новую ВМ из этого образа и запустите её.
Note
Для получения доступа к Акуре откройте агенту Failback порты tcp/443 и udp/12201.
Процедура Failback для OpenStack#
Чтобы запустить Failback, нажмите на пункт меню Failback на левой боковой панели.
Failback включает в себя пять (для партнёра) или четыре (для клиента) шага.
Рассмотрим последовательность для партнера.
Шаг 1. Выберите клиента
Шаг 2. Выберите тип целевого облака
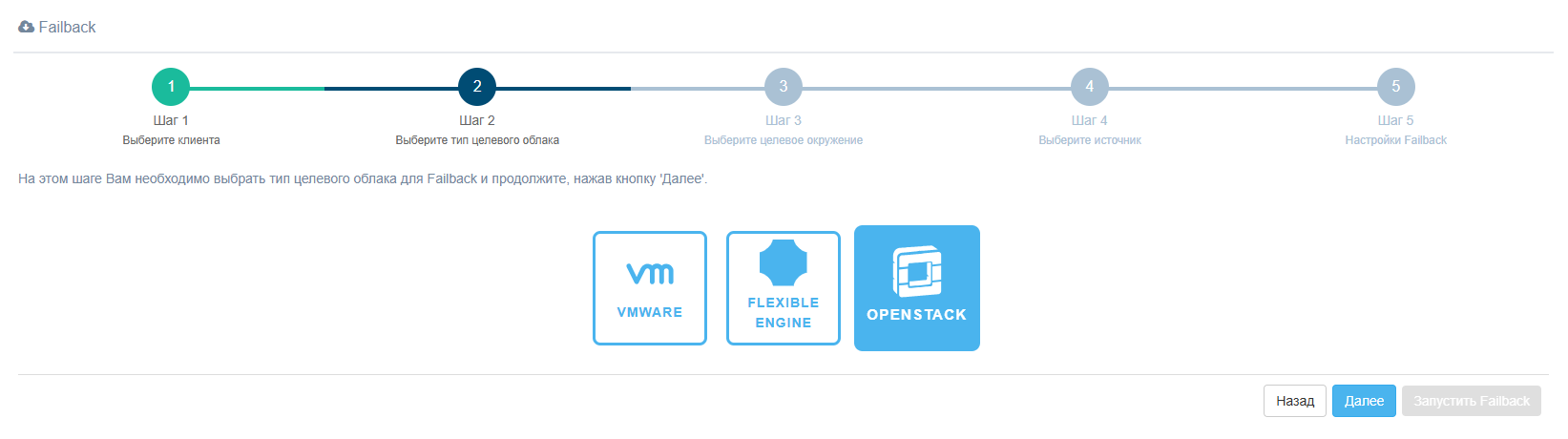
Шаг 3. Выберите целевое окружение
Выберите уже зарегистрированный OpenStack из списка или добавьте новый.
Note
В данной инструкции мы приводим последовательность действий в случае, если в процессе Failback вы захотите настроить новое облако. Однако, рекомендуем делать это заранее, до запуска Failback.
Для регистрации нового облака Failback необходимо заполнить следующие поля:
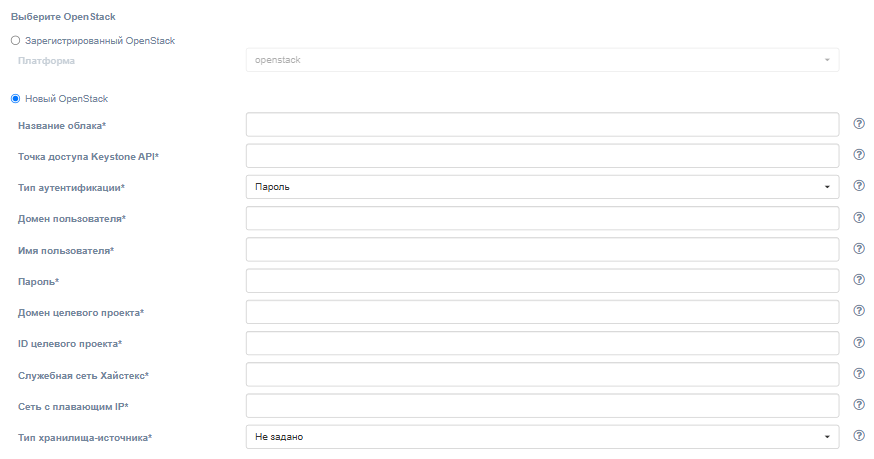
| Поле | Описание | Пример |
|---|---|---|
| Название облака | Название облака для отображения в пользовательском интерфейсе (должно быть уникальным). | Failback cloud |
| Keystone API endpoint | Аутентификационный URL Keystone | http://controller.example.com:35357/v3 |
| Тип аутентификации | Выберите тип аутентификации для Keystone API. | Пароль |
| Домен пользователя | Доменное имя пользователя для доступа к OpenStack | default |
| Имя пользователя | Имя пользователя для доступа к OpenStack | admin |
| Пароль | Пароль для доступа к OpenStack | passw |
| Домен целевого проекта | Целевой домен проекта OpenStack | default |
| ID целевого проекта | ID проекта, в котором будут размещены реплицируемые объекты | 39aa9af2e620404984f6d53a964386ef |
| Служебная сеть Хайстекс | Сеть, которая будет использоваться для failback-машин Хайстекс | provider |
| Сеть с плавающим IP | Внешняя сеть, которая будет использоваться для подключения плавающих IP-адресов к перенесённым машинам | admin_external_net |
| Тип хранилища-источника | Выберите хранилище для получения данных. Агент репликации для OpenStack требует задать хранилище, другие виды агентов настройки хранилища не требуют и не используют. | Не задано |
| Уровень поиска машин | Уровень поиска репликационным агентом виртуальных машин. Например, уровень “Зона доступности” означает, что в каждую зону доступности в проекте следует установить одного (и только одного) репликационного агента. Каждый агент будет находить машины только в соответствующей зоне доступности. | Весь проект |
Шаг 4. Выберите источник
Выберите Cloud Site и машины для процесса Failback, заполните поля Конфигурация и ID подсети. После заполнения всех полей кнопка Далее становится активной.

Шаг 5. Настройки Failback
Note
В случае, если Failback-агент не был установлен предварительно, при переходе на пятый шаг его нужно обязательно скачать и развернуть на его основании машину. Не запускайте Failback пока агент не будет установлен!
Задайте название для Failback. Поля Конфигурация, ID подсети и IP заполняются на основании параметров, введенных на четвертом шаге.
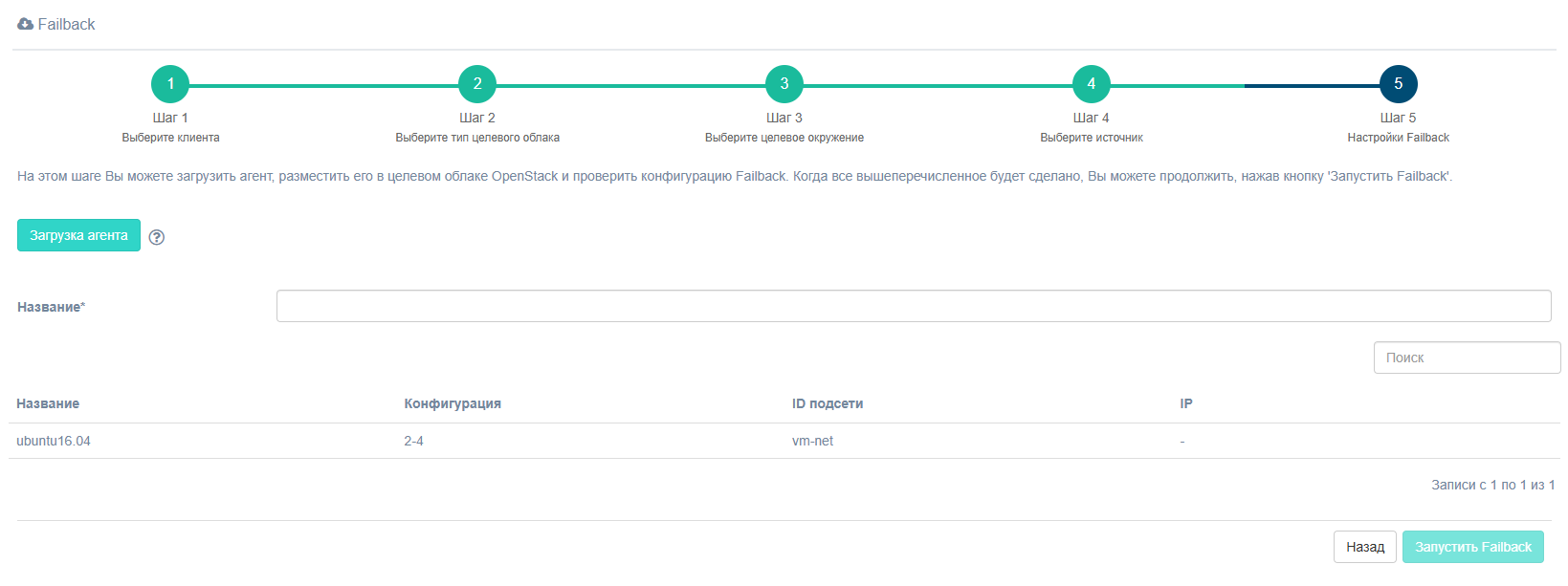
Повторно скачать файл агента можно на странице клиента Управление облаками.
Failback в другие облака#
Для других облаков Failback выполняется в форме оперативной обратной миграции рабочих нагрузок в исходную среду. Внутренние агенты репликации устанавливаются непосредственно на отказоустойчивых машинах.
Все репликации выполняются в фоновом режиме и не требуют каких-либо простоев при failover до окончательного отключения. Вы можете запускать неограниченное количество тестовых Failback / миграций.
Пожалуйста, свяжитесь с вашим поставщиком услуг или Хайстекс, чтобы получить инструменты для миграции.