
В условиях стремительного развития бизнеса и информационных технологий устойчивость ИТ-инфраструктуры и способность быстро восстанавливаться после сбоев становятся не просто желательными, а жизненно необходимыми. Основу любой стратегии аварийного восстановления составляют два ключевых показателя: RTO (время восстановления) и RPO (точка восстановления данных). Они позволяют компаниям оценивать допустимые потери данных и максимально приемлемое время простоя систем. Эти метрики лежат в основе планирования резервного копирования, хранения данных и обеспечения непрерывности бизнес-процессов.
Особенно актуальны эти вопросы для компаний, работающих в России. В условиях повышенной регуляторной нагрузки, нестабильности поставок оборудования и программного обеспечения, а также растущих киберрисков, грамотное управление RTO и RPO становится важным конкурентным преимуществом. Компании, которые заранее продумывают сценарии восстановления и инвестируют в отказоустойчивую архитектуру, снижают риски простоев и потери данных, что особенно важно в сферах с высокой стоимостью минуты простоя, от финансового сектора до ритейла.
В этой статье мы разберём, что такое RTO и RPO, зачем они нужны, как определить приемлемые значения этих параметров для вашего бизнеса и какие подходы помогают эффективно ими управлять.
Показатели RTO и RPO в аварийном восстановлении
Эти два понятия часто идут рядом, но важно понимать их по отдельности.
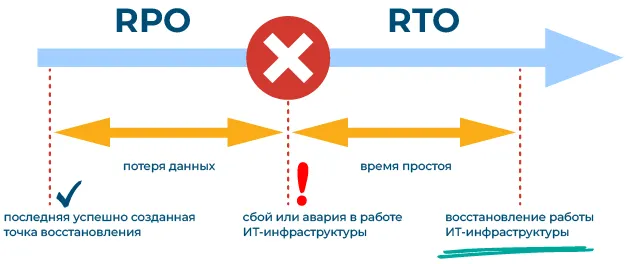
RPO (Recovery Point Objective) — это целевая точка восстановления. Проще говоря, она показывает, какой объём данных может быть потерян в случае сбоя. Например, если RPO — один час, значит, данные сохраняются каждый час, и в случае сбоя всё, что было сделано за последние 60 минут, исчезнет. Чем чаще вы прибегаете к использованию средств резервного копирования, тем меньше потерь — но и тем выше нагрузка на систему.
Максимальная защита — это когда данные копируются мгновенно, в режиме реального времени (так называемая синхронная репликация). Это обеспечивает RPO, равный нулю, но такая схема требует мощного канала связи и может заметно замедлить работу системы. Поэтому её используют только там, где важна каждая секунда.
RTO (Recovery Time Objective) — это целевое время восстановления. Он определяет, сколько времени потребуется, чтобы восстановить работу системы. То есть не сколько данных вы потеряете, а как быстро сможете продолжить работу. Если для вас критично вернуться «в строй» за 15 минут, RTO должен быть 15 минут, и под это уже нужно выстраивать ИТ-решения и процессы.
В отличие от RPO, RTO почти не связан с тем, насколько защищены ваши данные. Он больше про то, как быстро компания может снова начать работать. И для многих бизнесов это важнее. Если у вас, например, онлайн-магазин или банк, где даже несколько минут простоя — это потерянная прибыль, то RTO становится ключевым параметром.

Почему RPO и RTO критичны для disaster recovery и backup?
И RTO, и RPO — это не просто технические термины, а важные ориентиры, которые помогают понять, сколько времени и данных может позволить себе потерять компания в случае сбоя. Один определяет допустимую частоту создания резервных копий, второй — время, необходимое для восстановления работы. Вместе они помогают выстроить систему, способную пережить непредвиденные ситуации без серьёзных последствий.
Почему это критично? Потому что в современных условиях время — это деньги, а данные — это основа работы большинства компаний. Для бизнеса в России, особенно в сферах с высокими требованиями к непрерывности процессов (финансы, ритейл, промышленность, логистика), простои и потеря данных — не просто технические проблемы, а прямые финансовые и репутационные риски. Даже короткое отключение может повлечь за собой цепную реакцию проблем. А если при этом ещё и теряются данные, то ущерб может быть многократным. Поэтому чётко определённые и грамотно реализованные RTO и RPO — это не просто технический вопрос, а вопрос устойчивости и, в конечном счёте, выживания бизнеса.
Если эти параметры не заданы или не соответствуют реальным рискам, последствия могут быть серьёзными. Например:
- Пользователи не смогут оформить заказы или воспользоваться услугами — это прямые потери клиентов и выручки.
- Может быть нарушено законодательство о защите персональных данных, включая требования ФЗ-152.
- Репутационные потери и снижение доверия со стороны партнёров и клиентов — особенно если сбои происходят регулярно или сопровождаются потерей данных.
Главное — понимать, какие данные и процессы действительно критичны. Где допустимы небольшие отклонения, а где важна безотказность. Чем точнее определены RTO и RPO с учётом реальных бизнес-рисков, тем устойчивее работает ИТ-инфраструктура — и тем меньше поводов для беспокойства при внештатных ситуациях.
Функция Double Storage в Хайстекс Акура помогает восстановить данные приложений, инфраструктуру за минуты и при этом экономить на хранении. Узнайте больше →
В чем разница между RPO и RTO?
Вопрос звучит просто, но на практике различия между этими двумя параметрами часто вызывают затруднения даже у тех, кто регулярно работает с ИТ-инфраструктурой. Чтобы упростить: RPO показывает, сколько данных может быть потеряно при сбое, RTO — сколько времени можно позволить себе не работать, пока система восстанавливается. Оба параметра задают целевые рамки, в которые должны укладываться ИТ-службы или подрядчики, отвечающие за резервное копирование и восстановление. Но на этом сходство заканчивается. Эти показатели отвечают за разные задачи и не заменяют друг друга.
RPO напрямую связан с частотой создания резервных копий. Чем он меньше, тем чаще копируются данные и тем меньше потенциальные потери. Этот процесс легко автоматизировать, и он, как правило, работает в фоновом режиме. RTO, в свою очередь, определяет, сколько времени потребуется, чтобы запустить сервисы и восстановить доступ к данным после сбоя. Это более комплексная задача, зависящая от архитектуры системы, оборудования и готовности персонала. В отличие от RPO, здесь многое делается вручную, и автоматизация даёт гораздо меньше эффекта.
На практике приходится находить баланс между этими двумя показателями. Где-то критична минимизация потерь данных, где-то важнее сократить время простоя. Задача компании — определить, какие системы требуют максимальной защиты, и вложить ресурсы туда, где сбой может нанести наибольший ущерб.
Как определить и рассчитать RPO и RTO?
Вычислить подходящее значение RPO несложно, если чётко понимать, какой объём данных организация может позволить себе потерять без ощутимого ущерба. Например, если без последствий выдержит потерю информации за последний час работы, значит, RPO можно установить на уровне 60 минут.
Значение напрямую зависит от специфики бизнеса. Для компании, занимающейся, например, графическим дизайном с интенсивной работой над файлами, даже 15 минут без backup могут оказаться критичными. А вот для проекта, где данные обновляются редко, интервал может составлять несколько часов или даже дней.
Чтобы рассчитать RPO, нужно определить максимально допустимый промежуток времени, в течение которого потеря данных не приведёт к финансовым или операционным потерям. При этом важно учитывать разные сценарии: кибератаки, сбои оборудования, стихийные бедствия, человеческий фактор. Каждый из них по-своему влияет на бизнес, и в каждом случае возможный ущерб будет отличаться. Чем точнее вы сможете оценить последствия таких инцидентов, тем обоснованнее будет выбранная точка восстановления.
При расчёте RTO акценты немного другие. RTO показывает, сколько времени система может оставаться недоступной, прежде чем последствия станут критичными. Чтобы определить этот показатель, важно ответить на несколько ключевых вопросов:
- Что произойдёт, если система полностью выйдет из строя?
- Насколько критичен простой и какие потери он повлечёт?
- Сколько времени компания реально может позволить себе на восстановление?
- Где находятся слабые места в текущей инфраструктуре?
- Какие меры уже внедрены для защиты ключевых активов?
- С какими угрозами бизнес сталкивается чаще всего?
Эти данные помогут понять, насколько быстро нужно реагировать при сбоях и какие ресурсы следует задействовать для минимизации простоя. Правильно рассчитанное RTO — это не просто число, а ориентир, который позволяет грамотно выстраивать процессы восстановления и инвестировать в то, что действительно важно.
| Критичность системы | RPO (целевая точка восстановления) | RTO (целевая время восстановления) |
|---|---|---|
| Высокая (например, ERP, CRM) | 5–15 минут | 15–30 минут |
| Средняя (например, BI, отчеты) | 1–4 часа | Есть, дополнена инструментами управления |
| Низкая (архивы, тестовые среды) | 12–24 часа | до 1 суток |
Оставьте почту и мы расскажем, какие сценарии восстановления подойдут именно вам.
Практики управления RPO и RTO
Чтобы показатели восстановления действительно работали на бизнес, важно не просто их задать, нужно выстроить систему, которая поддерживает эти значения на практике. Ниже — ключевые принципы, которые помогут управлять RTO и RPO эффективно и без сюрпризов.
1. Регулярное и продуманное резервное копирование
Резервное копирование должно выполняться в соответствии с установленными значениями RPO — настолько часто, насколько это позволяют бизнес-процессы и технические возможности. Важно не только выполнение резервного копирования, но и хранение созданных копий в надежных и защищенных местах — желательно в разных средах (локально, в облаке, офлайн). Чем выше частота копирования, тем меньше потенциальные потери. Это позволяет сократить RPO без чрезмерной нагрузки на систему.
Но одного бэкапа для бизнеса недостаточно, чтобы защитить ИТ-инфраструктуру. Разбираем в деталях →
2. Постоянное тестирование планов восстановления
Даже самый продуманный disaster recovery plan (план аварийного восстановления) остаётся теорией, пока не будет проверен на практике. Регулярно проводите тесты восстановления, моделируя реальные сбои. Это позволяет выявить уязвимости и убедиться, что при необходимости всё действительно восстановится в допустимые сроки. Также важно обеспечить репликацию данных в другой дата-центр или облако (в том числе по модели cross-cloud). Это помогает приблизиться к RPO, равному нулю.
3. Актуальность и адаптивность
Показатели RTO и RPO не являются постоянными. По мере развития бизнеса, модернизации ИТ-инфраструктуры или внедрения новых технологий эти параметры нужно пересматривать. Это помогает сохранять баланс между затратами и уровнем защиты без потери гибкости.
4. Обучение команды и повышение готовности
Современные решения по резервному копированию и аварийному восстановлению, такие как Хайстекс Акура, позволяют автоматически создавать сценарии восстановления и существенно сокращают RTO. Но даже при наличии автоматизированных систем человеческий фактор остаётся решающим. Все сотрудники, вовлечённые в процесс восстановления, должны понимать, что такое RTO и RPO, и как действовать в случае сбоя.
5. Многоуровневая система резервного копирования
Облачное резервное копирование в совокупности с локальными и внешними (offsite) копиями повышают устойчивость системы и позволяет гибко реагировать на разные типы сбоев. Такой подход помогает одновременно снизить и RPO, и RTO.
6. Мониторинг и контроль
Значения RTO и RPO должны быть зафиксированы в SLA и регулярно пересматриваться. Автоматический мониторинг позволяет отслеживать соблюдение целевых показателей и оперативно реагировать на отклонения.

В заключение: Оптимизация RPO и RTO для минимизации бизнес-рисков
Чем точнее организация определяет свои целевые значения RPO и RTO, тем эффективнее она может управлять рисками, связанными с потерей данных и простоем систем. Эти параметры — не просто технические числа, а инструменты бизнес-контроля, позволяющие принимать взвешенные решения и сохранять стабильность при любых сбоях.
Решение «Хайстекс Акура» предлагает надёжные сценарии для реализации системы резервного копирования и аварийного восстановления, обеспечивая оптимальные значения RPO и RTO в соответствии с задачами заказчика. Мы помогаем минимизировать время простоя, снизить потери данных,поддерживать высокую доступность ИТ-сервисов и обеспечивать бесперебойную работу информационных систем
🔖 Если вам необходимо надежно и быстро осуществить миграцию ВМ, бизнес-приложений на другую платформу виртуализации или облако, решение «Хайстекс Акура» сможет вам помочь →